
| |
|
|
| 首页 淘股吧 股票涨跌实时统计 涨停板选股 股票入门 股票书籍 股票问答 分时图选股 跌停板选股 K线图选股 成交量选股 [平安银行] |
| 股市论谈 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 商业财经 科技知识 汽车百科 工程技术 自然科学 家居生活 设计艺术 财经视频 游戏-- |
| 天天财汇 -> 科技知识 -> 计算机上“中断”的本质是什么? -> 正文阅读 |
|
|
[科技知识]计算机上“中断”的本质是什么? |
| [收藏本文] 【下载本文】 |
|
以硬件中断为例,当外界发生中断时,中断信号经过中断控制器,最终达到CPU的中断引脚上,这个信号会修改中断寄存器,CPU是如何知道中断发生的?我的理解:… |
|
中断相当于一个硬件实现的表跳转语句,它并不是轮询。 |
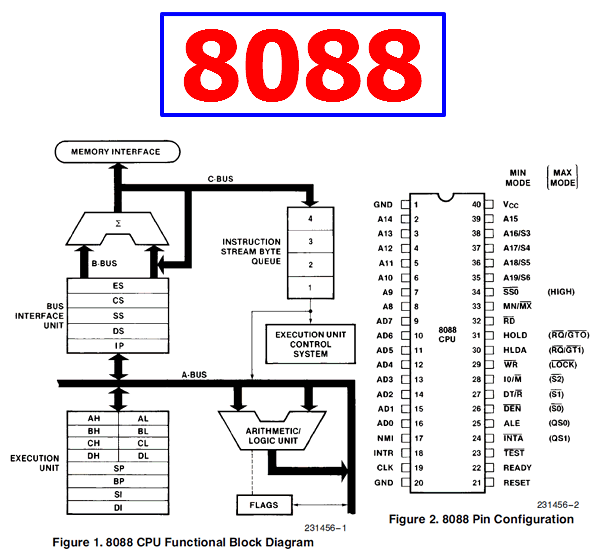
|
|
以8088为例,它的17号引脚NMI接受不可屏蔽中断信号,18号引脚INTR接受可屏蔽中断信号;当CPU决定响应中断时,在24号引脚输出一个信号,通知外部自己将执行中断操作。 至于内部……上面的框图没画中断控制器。它大概是这样的: |
|
|
各种中断信号(包括外部的NMI、INTR/IRQ以及内部的除零错、单步执行/TRAP等等),都会接入中断处理逻辑电路。中断处理逻辑电路的信号进一步送到指令解码器电路中。 指令解码器每次解码/执行一条指令时,都会考虑中断信号。 这就好像火车轨道一样,指令解码器正常的执行动作是,解码一条指令,执行,然后修改PC,使其指向下一条指令,如此反复。 但一旦产生了中断信号,那么当前指令执行之后,指令解码器马上切换到另一条轨道上;这条轨道内置了一条中断指令,迫使CPU开始处理中断。 注意这个检测是不需要消耗时间的。只是需要一些门电路而已。形象点说,它就好像一个电磁控制的单刀双掷开关,有中断且CPU没有关中断时,下一条指令执行前,电流就直接送给中断处理逻辑了。因此说这是个无消耗的检测,并不是执行了一条if语句反复判断――这头输入信号另一头直接出结果,这是硬件实现和软件实现最根本的区别,也是我们总说硬件实现比软件实现快的多得多的根本原因。 |

|
|
中断就相当于外设自顾自的扳了CPU的道岔:它不需要检测什么,到了就必须沿着道岔接通的方向走。 当CPU处理外部中断时,如你所见,8088只有一个中断信号引脚。但这并不意味着它只能连接一个外设、仅能处理一个中断。 事实上,外部会通过一个“或”电路把一系列中断接入8088的18号INTR脚。我们知道,或门是“任何一个设备产生了中断,INTR脚都会收到中断信号”;于是8088进入中断逻辑。 但,8088怎么知道究竟是哪个设备请求中断服务呢?如果多个设备同时发来中断请求,它发出的中断响应信号会不会同时激活多个设备? 答案是:你应该这样连接它的24号中断响应脚: |
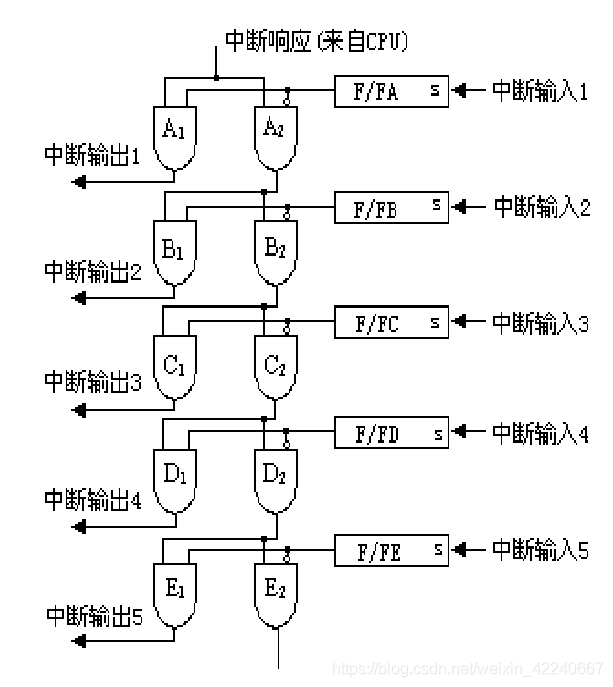
|
|
其中,A1~E1这一串与门确保只有当前中断源有中断、且CPU发出了中断响应信号,对应的硬件线路才会有中断输出信号。 这是怎么做到的呢? 注意,自B之后的与门,它的一路控制信号来自A2~E2,而不是直接来自CPU。而A2~E2这一串与门反相了中断输入。它的意思是,一旦靠前的设备有中断,那么CPU发出的中断信号就不会往下一级传递;只有靠前的设备没有发出中断时,后面的设备才能收到CPU的中断响应信号。 换句话说,这是一个硬件优先级电路,靠后者优先级更低。 当然,这是分立元件自己实现的中断优先选择电路。你也可以用intel的8059A中断控制器控制中断优先级――原理是差不多的。 中断控制器也可以做在CPU里面,使得CPU“天生”就对外引出N个引脚、可以同时处理N个中断源――但原理仍然是差不多的。 当外部电路识别了“中断输出号码”时,可以通过另外一个电路在指定位置设置当前设备号、然后CPU就可以通过数据总线读取设备号,继而一步算出中断向量所在的内存位置;也可以直接修改“当前中断向量的偏移”,使得CPU一步跳转到中断服务程序。这里都是可以灵活设计的。 但,无论如何,CPU并不是必须执行轮询的(事实上,个人认为,如果这里弄出了轮询,就说明CPU设计者是个新手、外行:因为信号直通电路简洁、响应速度极快;弄成轮询反而逻辑复杂、响应极慢)。它只需要通过24号引脚输出一个电压,就立即激活了相关电路、使得目标设备号/中断向量值等信息立即就绪――下一步保存当前指令指针寄存器内容并跳转到对应中断服务程序即可。 以上都可以在一个指令周期内完成。因此,重复一遍,这里没有轮询(当然,你一定要搞个轮询出来也是可以的;但除了行为艺术似乎看不出什么必要)。 你可以认为这是一个硬件实现的“表跳转”逻辑,一个时钟周期直接完成切换;没有中断的设备压根不会得到通知或者检查――它们预先把单刀双掷开关扳到了正确的电路上,然后CPU给电路加电,正确的响应信号立即就出来了。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
好问题,我们先思考,如果计算机没有中断,该如何知道外部来数据了? 一般来说,外部数据到来的时候,cpu的某个引脚,收到电信号,引脚相关的寄存器会被写入相关的值,但此时并不会改变cpu的执行流程,cpu其实很傻的,它只能机械的读取指令寄存器的值,这个值是一个内存地址,cpu从这个内存地址取出要执行的指令,开始执行,当执行结束,继续读取指令寄存器的值执行,然后一直重复这个流程; 要想让cpu处理这个引脚上的数据,只能在业务代码里写个大循环,这个循环会监听每个引脚上相关寄存器值,判断是否有数据到达,如果有了就开始处理,这个就是你说的轮询; 但这种机制有个问题,就是性能问题,cpu为了保证能及时响应外部数据,必须一直处于循环状态,在循环里面检查每个引脚的状态,但是这个样会消耗cpu,从而耗电,因此没有数据到达时会浪费大量的CPU周期,导致能耗增加。在单片机领域,能耗是非常重要的,很多单片机不能长期插着电源。 那我们假设耗电不是问题,那还有问题吗?有的,cpu除了检查引脚,还得处理业务逻辑,那处理业务逻辑的过程中,如果外部来数据了了怎么办?有2种办法,要么在当前任务执行结束后开始检查cpu的引脚,显然不行,因为不知道当前任务要多久结束,很多请求都要求快速响应。要么使用类似时间片的机制,让每个任务最多执行1ms,然后再去检查。可以看的出来,这种机制下cpu对外部数据的响应最少会有1ms的延时,1ms在单片机领域已经是一个比较大的数字了,所以这种方式还是有问题。 基于以上的问题,cpu的设计者想到了中断的机制,cpu给某几个特殊的引脚设计好了电路,一旦这几个引脚收到数据,那么就根据引脚的数据直接修改相关指令寄存器的值,这玩意是在硬件上处理的,优先级很高,无视当前正在运行的逻辑,直接修改了计算机的下一个指令,这个指令对应好了预先配置好的程序,这些特殊程序就是专门负责处理外部中断请求的。 这些程序内部会先把之前业务的上下文,例如寄存器的值等保存起来,然后根据中断信号执行相关的逻辑,当中断程序执行完之后,在把之前业务逻辑的上下文(寄存器的值)从内存取出来,接着执行之前的业务逻辑,在这样的流程里面,当有外部数据到达的时候,cpu最多延时一个指令周期,而且还不用让cpu一直不停的轮询,这就是cpu中断的基本原理与产生背景。 有人会问,你这硬中断的逻辑,不也是业务逻辑吗?那如果这期间新的中断来了咋办?答案是,硬中断的逻辑要求尽可能的快,比方说你是门卫,有个人找你要见某某人,你打个电话就好了,你别亲自带着他去公司里面找。 你说不行啊,有些事情要做的事情太多,实在没法很快结束,咋办?现在的操作系统有软中断机制,也叫二级中断,专门用来辅助硬中断的,可以理解为门卫的小弟,门卫收到请求后,发现太麻烦,让小弟在后面处理,软中断其实就是个优先级不那么高的程序,他可以慢慢在后面执行。 tcp的数据包处理,就是有关中断的经典例子,数据到达的时候先触发cpu一个硬中断,为了尽可能快,硬中断程序一般仅仅标记网卡设备有数据了,详细处理网卡数据的逻辑会放在软中段里面处理,硬中断退出的时候,会顺便触发软中断执行一次,在软中断里慢慢处理网卡传递过来的数据。 当然,实际中的中断还需考虑一些问题,例如中断处理中,另外一个很重要的中断来了,中断也是可以临时处理其他紧急中断的,这里需要打断旧的中断,这涉及到优先级以及优先级翻转的问题。还有中断的逻辑是不能产生任务调度的逻辑,例如使用互斥锁锁等。如果你有兴趣,可以查看专业的书籍,这里只做了基本的原理说明,如果觉的对你有帮助,帮忙点赞或者关注,您的点赞是我的动力,我将持续创作有关计算机基础的文章。 |
|
教材上会说中断是外部设备向处理器发起的请求事件,但这还不够本质。中断的本质是处理器对外开放的实时受控接口。 一个没有中断的计算机体系是决定论的:得知某个时刻CPU和内存的全部数据状态,就可以推衍出未来的全部过程。这样的计算机无法交互,只是个加速器。 添加中断后,计算机指定了会兼容哪些外部命令,并设定服务程序,这种服务可能打断当前任务。这使得CPU“正在执行的程序”与“随时可能发生的服务”,二者形成了异步关系,外界输入的引入使得计算机程序不再是决定论。由人实时控制的中断输入,是无法预测的。再将中断响应规则化,推广开,非计算机科学人群就能控制计算机,发挥创造力。 电竞鼠标微操,数码板绘,音频输入合成,影像后期数值调整,键盘点评天下大势,这些都不是定势流程,是需要人实时创造参与其中的事件,就由中断作为载体,与计算机结合了起来。 中断就是处理器的标准输入接口。 至于硬件细节并不那么重要,取决于指令规范。可以直接拉外部引脚到CPU Retire单元;也可以内置一个中断控制器统筹接收外部信号,再做转发。x86上二者都有,后一项是由南桥发至IO APIC再发至核心APIC再发给Retire单元,而CPU也有一定的自由度,会在适当的时机响应。 |
|
我们知道由于操作系统将程序执行状态划分为内核态和用户态,而CPU 上会运行两种程序,一种是操作系统内核程序,一种是应用程序,在合适的情况下,操作系统内核会把CPU的使用权主动让给应用程序(进程管理),由内核态切回用户态。 而“中断”是让操作系统内核夺回CPU使用权的唯一途径。 |
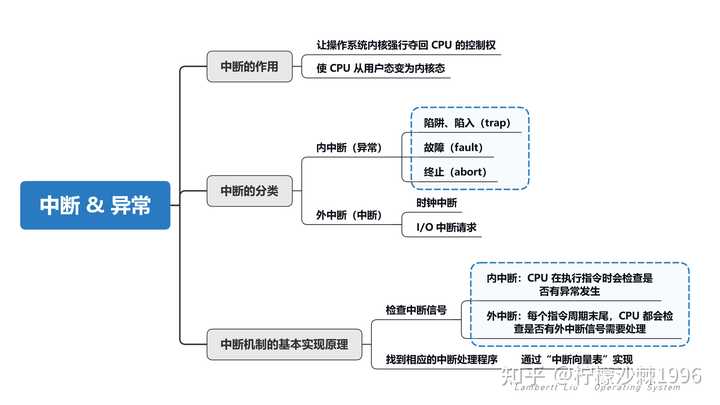
|
|
1.中断和忙等待 中断(Interrupt),指处理器接收到来自硬件或软件的信号,提示发生了某个事件,应予以注意,这种情况就称为中断。 中断是让操作系统内核夺回CPU使用权的唯一途径,如果没有中断机制,那么一旦应用程序上CPU运行,CPU就会一直运行这个应用程序。这就与操作系统的并发属性产生冲突。 中断的设计之初,是用以提高计算机工作效率、增强计算机功能。最初引入的硬件中断,只是出于性能上的考量,如果计算机系统没有中断,则处理器与外部设备通信时,它必须在向该设备发出指令后进行忙等待(Busy waiting),反复轮询该设备是否完成了动作并返回结果。这就造成了大量处理器周期被浪费。 |
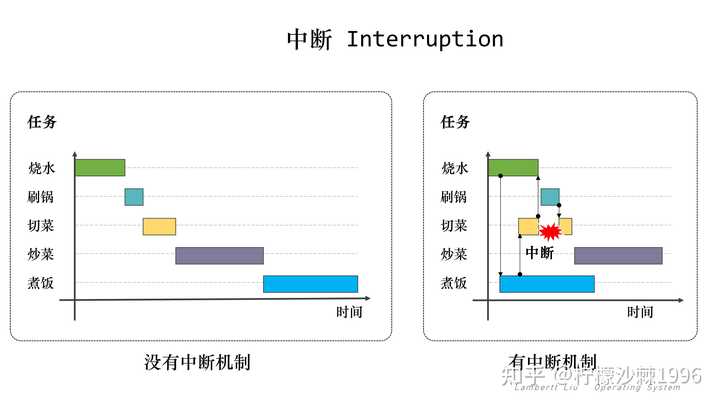
|
|
初看这句话,会觉得难以理解,为什么中断还反而提高了效率?我在做事的时候,最讨厌别人打断我了,这会严重降低我的效率。 对比现实世界,这个中断,其实很好理解。比如我是一个厨子,我现在要做一顿饭,需要烧水、刷锅、切菜、炒菜、煮饭这几个步骤,但是我相信没有人会傻到,把这几件事情一件一件地干完。这样非常浪费时间,我可以把水烧了,就开始去煮饭,等锅在煮的时候,自己去切菜,等水烧开了,然后先把手头的事情放下,那么把水装到水壶里,再去刷锅,然后等这些做完了,在回头去切菜。 与中断对应的是忙等待。这里的忙等待,是指一种进程执行状态。进程执行到一段循环程序的时候,由于循环判断条件不能满足而导致处理器反复循环,处于繁忙状态,该进程虽然繁忙但无法前进。 忙等待,在现实世界里,就是一直不停的等着别人做,然后等别人做完了,自己再做。就很像那种身边讨厌的人,自己的活没做完,但是总是催着别人做。这样的效率其实并不高,反倒是在得知别人还没做完的时候,先做自己的事情,然后等自己做的差不多了,然后再跑过来对齐下进度。 |
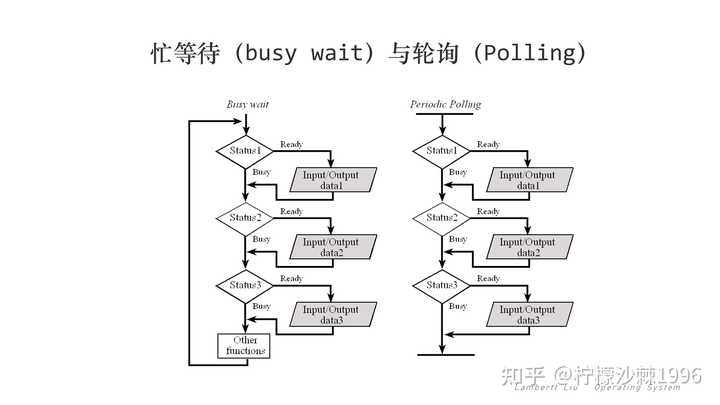
|
|
回到中断一开始引入的目的,在引入硬件中断以后,当处理器发出设备请求后就可以立即返回以处理其他任务,而当设备完成动作后,发送中断信号给处理器,后者就可以再回过头获取处理结果。这样,在设备进行处理的周期内,处理器可以执行其他一些有意义的工作,而只付出一些很小的切换所引发的时间代价。 后来,用于CPU外部与内部紧急事件的处理、机器故障的处理、时间控制等多个方面,产生了通过软件方式进入中断处理(软中断)的概念。 回顾整个中断,其实是和操作系统的并发性一脉相承,由于操作系统的并发性让多个程序并发执行,所以在需要一种切换机制,这就是中断。 2.中断过程 中断的过程发生如下: |
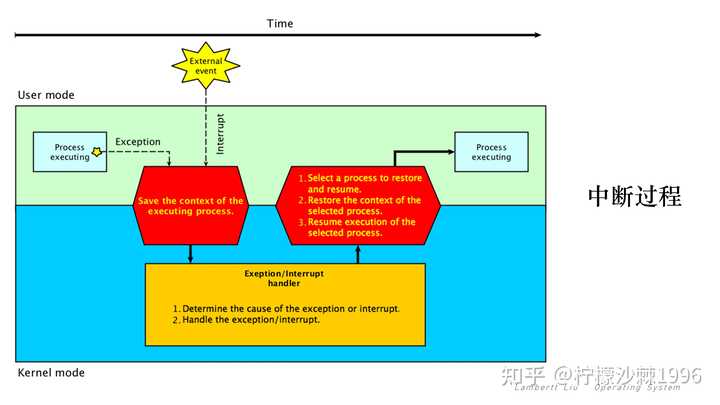
|
|
当发生异常或中断时,执行会从用户模式转换到处理异常或中断的内核模式。具体来说,必须采取以下步骤来处理异常或中断: 进入内核,必须首先将当前正在执行的进程的上下文(所有 CPU 寄存器的值)保存到内存。 内核现在已准备好处理异常/中断。 1. 确定异常/中断的原因。 2. 处理异常/中断。 处理完异常/中断后,内核将执行以下操作步骤: 1. 选择要还原和恢复的进程。 2. 恢复所选进程的上下文。 3. 恢复所选进程的执行。 因此,回到一开始的问题。中断的本质是什么?中断的本质就是发生中断就意味着需要操作系统介入,开展管理工作。 按照实际的分类,中断分为外中断和内中断。 3.内中断和外中断 内中断指,与当前执行的指令有关,中断信号来源于CPU内部。外中断指,与当前执行的指令无关,中断信号来源于CPU外部。一般而言,狭义的中断特指外中断,而内中断很多时候也叫做异常和例外。所以在上图中,由用户态切换成内核态的原因可能由外部事件触发(中断)和内部程序执行异常(内中断)导致。 |
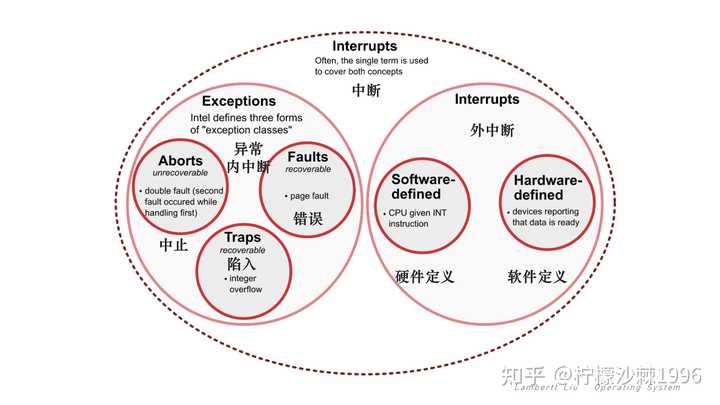
|
|
其中,内中断(Exception)的三种常见类型: 1. 陷入(trap):由陷入指令引发,是应用程序故意引发的,比如,read, fork, execve... 例如,某应用程序想请求操作系统内核的服务,此时会执行一条特殊的指令――陷入(trap)指令,该指令会引发一个内部中断信号。 系统调用(system call),就是通过陷入(trap)指令完成,由外部调用系统接口,完成用户态转化成内核态的状态。 2. 故障(fault):由错误条件引起的,可以被错误处理程序纠正并返回正常程序。内核程序修复故障后会把 CPU使用权还给应用程序,让它继续执行下去。 例如,缺页故障(Page fault),当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由中央处理器的内存管理单元所发出的中断。 3. 终止(abort):由致命错误引起,内核程序无法修复该错误,因此一般不再将CPU使用权还给引发终止的应用程序,而是直接终止该应用程序。 如:整数除0、非法使用特权指令。CPU发现当前状态非内核态,该行为是非法状态,引发中断信号(Signal),强行转化成内核态,然后运行处理中断信号的内核程序。 联想到做饭的例子,其实也可以类比现实世界。 比如我正在切菜,突然自己想起自己有些特别重要的事情急着做,比如有人马上来家做客,这个时候需要发下微信,问下别人到哪了,这个时候切菜的过程就中断了。这就类似于陷入,通过个人主观地中断去做另一件事。 或者,当我切菜的时候,突然发现自己少洗了一道菜,比如我要做西红柿炖牛腩,突然发现西红柿没有,这个时候我就要去超市临时买点西红柿,等买回来,在继续切菜。这是一种故障,是由于错误的条件引起(忘记备菜了),但是我可以很快去楼下买完回来继续做,不影响后面出菜。 最差的情况就是我切菜的时候,切到手了,鲜血直流,我得马上找布包扎上药膏,然后跟家人说,今天这个饭目前我是做不了,把活丢给了别人。这种就是致命错误导致的终止,而且无法修复,只能终止这个过程。 |

|
|
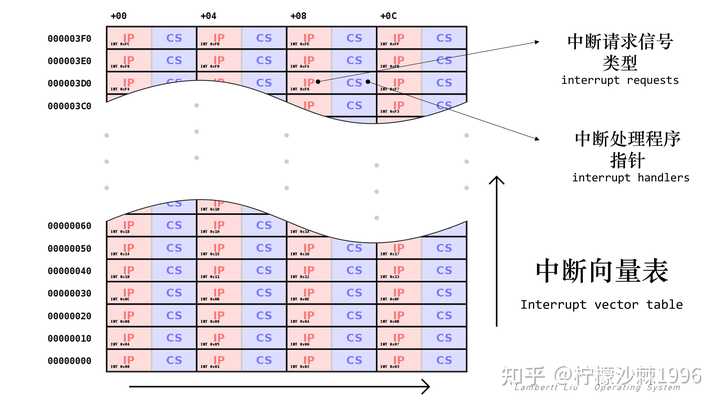
外中断的两种常见类型: 1. 时钟中断,由时钟部件发来的中断信号; 时钟部件每隔一个时间片(如 50ms)会给CPU发送一个时钟中断信号。CPU接受中断信号,转成内核态。 CPU处理时钟中断的内核程序,操作系统内核决定接下来让另一个应用程序上CPU运行。 2. I/O 中断请求: 当输入输出任务完成时,向CPU发送中断信号。处理I/O中断的内核程序。4.中断基本原理 不同的中断信号,需要用不同的中断处理程序来处理。当CPU检测到中断信号后,会根据中断信号的类型去查询中断向量表(interrupt vector table,IVT),以此来找到相应的中断处理程序在内存中的存放位置。这里的中断向量表,中断向量表 是一种数据结构,它将中断处理程序列表与中断向量表中的中断请求类型列表相关联。中断向量表的每个条目(称为中断向量)都是中断处理程序(interrupt handler,也称为ISR)的地址。 |
|
|
大多数处理器都有一个中断向量表,例如,常见的中断向量表的前几位有: 中断编号IVT 地址中断名称000-03CPU 除以零, CPU divide by zero104-07单步调试,Debug single step208-0B不可屏蔽中断, Non Maskable Interrupt (NMI input on processor)30C-0F调试断点, Debug breakpoints......... 显然,中断处理程序一定是内核程序,需要运行在“内核态”。 个人举出这样形象生动的例子,我觉得可以帮助回答下什么叫中断,以及为什么中断可以提高系统的运行效率。 个人GitHub链接: CS-Basic-SelfLearning-408/【OS】操作系统/42 操作系统运行机制、中断与异常、系统调用、体系结构 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
CPU 是个死循环,中断给你个跟他互动的机会。不然,它只能自顾自的转了。 中断是:CPU 循环的时候,你喊了他一嗓子。 轮询是:CPU 循环的时候,他喊了你一嗓子。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
题主对中断流程的理解,大体上是准确的,但对“CPU如何知道中断发生”以及“中断本质是轮询”的推论,值得去好好盘一盘。能把中断理解到“CPU每个指令周期去查看中断寄存器”这一步,说明确实深入思考到了硬件层面。但,也正是在这里,以及“本质”二字,开始产生了微妙的偏差。 一、CPU是如何“知道”中断发生的?――不是每个周期都“轮询”寄存器 CPU每个指令周期去查看中断寄存器,好像在说是CPU在不断地执行一个 while(true) { if(interrupt_register_is_set) { handle_interrupt(); } } 的微代码。如果真是这样,那CPU就真成了一个“轮询工”,只不过这个轮询发生在硬件指令层面,比软件轮询快了N个数量级而已。 但实际上脑袋秃秃的设计师们早就对其进行了优化。CPU并不是在每个指令周期的固定时间点去“读取”某个中断寄存器的值来判断。 更准确的描述是下面的三个步骤: 中断信号线(IRQ): 当外部设备(通过中断控制器)有中断请求时,它会拉高(或拉低)CPU上一个或多个特定的物理引脚。这不是一个通过总线读写寄存器的操作,而是一个电平信号的直接变化。指令执行间隙的“感知”: CPU在执行完一条指令后,准备取下一条指令之前,会检查这些中断引脚的电平状态。注意,这个“检查”是硬件控制逻辑的一部分,非常高效,不是软件意义上的“读取寄存器再判断”。可以想象成CPU在每条指令的“幕间休息”时,会“瞥一眼”门口的“紧急信号灯”是不是亮了。中断触发: 如果检测到中断引脚上有有效信号,并且该中断没有被屏蔽(通过中断屏蔽寄存器),CPU的控制单元就会改变正常的指令执行流程。它就会:完成当前指令(有些指令可能需要特殊处理,比如长指令)。保存关键的上下文(程序计数器PC、状态寄存器等)到栈中。根据中断源(可能通过中断控制器识别或CPU读取特定寄存器获得中断向量号)跳转到对应的中断服务程序入口地址。 |
|
|
所以,这里的关键区别在于你理解的是CPU主动、定期地“读”一个中断状态。而事实上是CPU在指令间隙被动地“感知”一个物理信号线的状态。 二、中断的本质,真的是“高效轮询”吗?―― 不,它是“事件驱动”中断的本质其实就是轮询,只是比直接在代码中轮询的效率高,反应快? 我的回答是:形似而神非。 如果仅仅从“CPU在某个时间点检查某个状态”这个极度简化的行为来看,确实有“检查”的动作。但“轮询”这个词,在计算机科学语境下,通常带有“主动、重复、消耗资源去查询状态”的含义。 中断的核心思想,与轮询截然相反,它是“事件驱动”的。 主动性 vs. 被动性。轮询状态下,CPU是主角,主动花费时间去挨个问:“你好了吗?你好了吗?” 如果设备大部分时间都没准备好,CPU就在做无用功。 而在中断状态下,设备是主角,CPU是被动响应者。CPU可以安心做自己的事情,直到设备“大喊一声:我好了!” CPU才去处理。 再看CPU利用率的对比。轮询即使没有事件发生,CPU也得周期性地执行查询代码,浪费CPU周期。对于低频率事件,轮询效率极低。对于中断来说,CPU平时不关心外设状态,可以100%执行用户程序或操作系统任务。只有当中断发生时,才切换去处理,处理完马上回来。CPU利用率大大提高。 那为什么会有这种“像轮询”的感觉? 你之所以会联想到轮询,可能是因为CPU确实是在“检查”中断线的状态。而这个检查发生在指令执行的间隙,有其固有的“周期性”(虽然不是固定时间周期,而是指令周期)。 但这种硬件层面的“检查”,其设计目标、效率和对系统整体行为的影响,与软件轮询有着本质区别。它不是为了“查询”,而是为了“感知突发事件”。如果中断的本质是轮询,那我们为什么还要费劲设计中断控制器、中断向量表、上下文切换这些复杂机制呢? 直接让CPU在固件里跑个极快的轮询循环不就完了?答案显然是否定的。 中断机制虽然在硬件层面存在一个“在指令周期结束时检查中断信号线”的动作,但这与我们通常理解的、以消耗CPU资源为代价的“轮询”有着根本性的不同。 所以将中断的本质归结为“高效轮询”,是对中断机制深刻内涵的一种降维理解。它捕捉到了表象,却错失了其灵魂――事件驱动的优雅与高效。 希望这个解释能让你对中断有更清晰、更本质的认识。如果文章对你有帮助,别忘了点赞关注一波~ 我是旷野,带你探索无尽技术! 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
cpu忙头干活ing... 键盘:cpu,我喊你一声你敢答应吗! cpu: 到到到!!有何吩咐 键盘:输入字母A! cpu: Over啦! cpu继续忙头干活ing... 鼠标:cpu,我喊你一声你敢答应吗! cpu: 到到到!!有何吩咐 键盘:我要活动一下 cpu: Over啦! cpu继续忙头干活ing... |
|
我觉得中断的英文interrupt一词本身就解释的足够清楚了,这里没有任何高深的东西,不用想的那么复杂。 什么是interrupt? 我们看下专业的英文词典是怎么解释这个词的: interfere in someone else's activity 看到了吧,直译过来是干扰其它人的事情。 这就是所谓interrupt的本质。 从计算机的语境来说就是硬件干扰CPU的事情。 CPU的什么事情呢?CPU只有一件事情那就是执行指令。 这里有这么几件事需要思考: 既然硬件能干扰到CPU的正常的指令执行,那么CPU就必须能感知到干扰信号,所谓的干扰信号就是这里所说的中断信号。 CPU的工作粒度是机器指令级别,那么在每条机器指令执行结束后都会检查一下是否中断信号产生。 题主觉得这里的实现像是在轮询,这其实是没有问题的,但这是及其高效的,这就好比你在玩游戏,此时如果有人喊你的名字(中断信号)干扰你玩游戏那么你立刻就能听到,但你的大脑有一直在轮询“有没有人喊我的名字?有没有人喊我的名字?有没有人喊我的名字?”了吗?并没有对不对,人脑的中断检查机制是及其高效的。 CPU的硬件特性决定中断处理机制也及其高效。 关于CPU的更详细讲解你可以参考这篇文章: 码农的荒岛求生:你管这破玩意叫 CPU ?5855 赞同 ・ 269 评论文章 |

|
|
最后也是最重要的,觉的有帮助的话给 @码农的荒岛求生 点个赞再走呗~ |

|
|
|
|
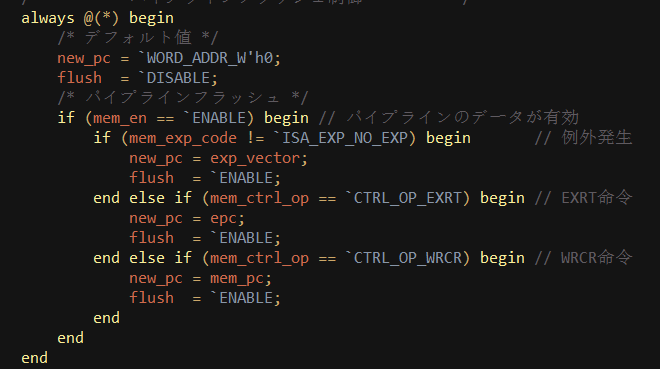
CPU是如何知道中断发生的,我们可以看下一个玩具级别的软核CPU是如何处理中断的: |
|
|
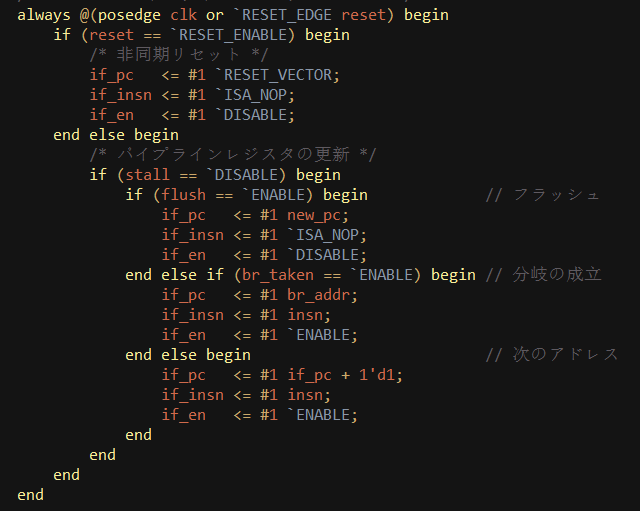
当中断产生时,将 exp_vector(异常向量地址)赋给new_pc。注意触发条件是always @(*) ,该动作的实现和时序无关。 在CPU时钟脉冲抵达时,PC寄存器被赋值为new_pc,即异常向量地址: |
|
|
于是,在下一次取指令地址时,CPU跳至中断向量地址。 参考书籍 CPU自制入门 |
|
硬件背景的理解 是触发不是轮询。 |

|
|
系统有一个叫中断向量表的东西,具体约定了某几个特定电路发生特定事件的时候(比如电压被上浮或者下拉),应该执行某个地址上的指令。 CPU在正常执行指令的时候,每执行一条指令,指令计数器增加1。逻辑上就是CPU在顺序执行下一条指令。 当触发中断时,系统读取中断向量表获取事件对应的地址,并强行将指令计数器置位到该地址。 CPU将在下一条指令直接跳转到对应地址,直到结束后ret。 |
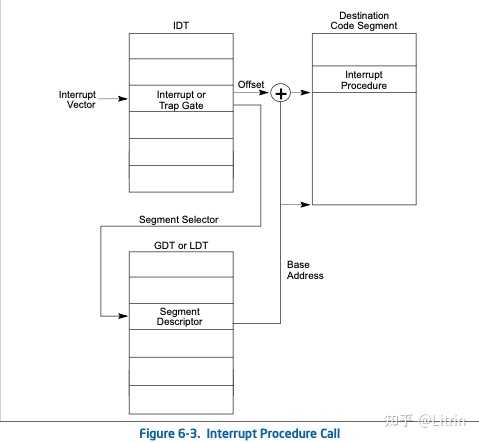
|
|
软件背景的理解 OS维护着一个中断事件列表以及事件对应的处理函数指针。 获取到了系统硬件的某一个改变,触发一个高优先级的函数抢占调用抢占当前线程的运行时间。直到任务结束后返回当前线程。 问题在于中断事件太多(x86只有8bit共计255个中断,还要和异常混用,早就被定义光了),无法为每一个事件单独定义,那么对于某些复杂场景就需要多种中断事件复用同一个函数指针。别管什么情况先调用函数,函数内部再根据逻辑判断事件是什么,这个时候就到轮询了。 日常生活背景的理解不管当时你在干什么,只要手机铃声一响,你就必须看一眼手机――中断和响应中断。为了提高效率,你给不同的应用配置不同的铃声以便知道是什么类型的消息――中断向量表。听到电话铃你会立即响应,xx应用弹窗你会选择性忽略――中断处理优先级。短信没必要理会,于是设置了短信一律静音――中断屏蔽。xx应用可以设置只有超过10条留言未读时才弹窗――中断合并。骚扰电话太多,又不敢直接关闭所有来电。只能先看一下手机,再根据对方来电是否在通讯录决定是否接电话――中断复用+中断处理的事件轮询。设置闹钟――定时器中断。定闹钟强制自己每分钟要看一下手机,否则就振铃――看门狗中断。电池快用完的时候会响一声――异常。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
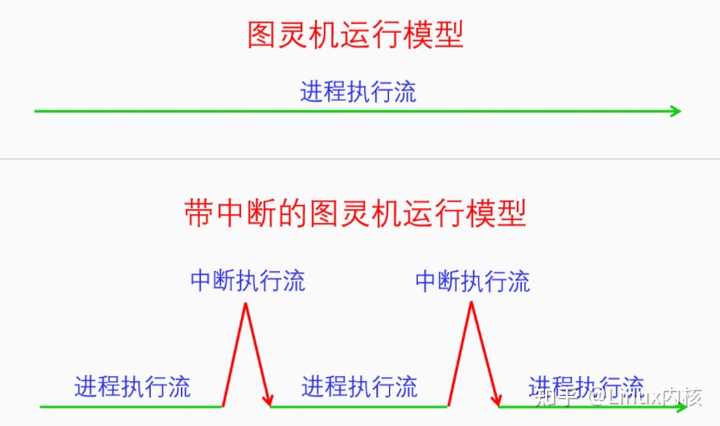
一、中断基本原理 中断是计算机中非常重要的功能,其重要性不亚于人的神经系统加脉搏。虽然图灵机和冯诺依曼结构中没有中断,但是计算机如果真的没有中断的话,那么计算机就相当于是半个残疾人。今天我们就来全面详细地讲一讲中断。 1.1 中断的定义 我们先来看一下中断的定义: 中断机制:CPU在执行指令时,收到某个中断信号转而去执行预先设定好的代码,然后再返回到原指令流中继续执行,这就是中断机制。 可以发现中断的定义非常简单。我们根据中断的定义来画一张图: |
|
|
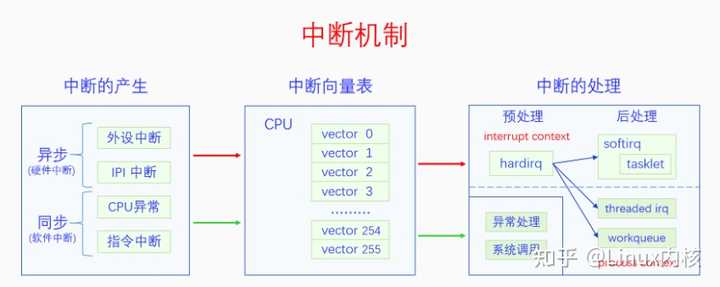
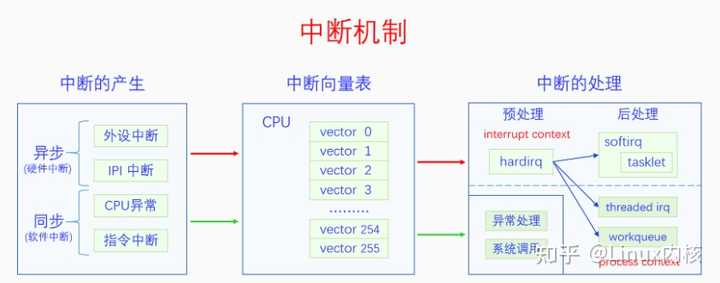
在图灵机模型中,计算机是一直线性运行的。加入了中断之后,计算机就可以透明地在进程执行流中插入一段代码来执行。那么这么做的目的是什么呢? 1.2 中断的作用 设计中断机制的目的在于中断机制有以下4个作用,这些作用可以帮助操作系统实现自己的功能。这四个作用分别是: 1.外设异步通知CPU:外设发生了什么事情或者完成了什么任务或者有什么消息要告诉CPU,都可以异步给CPU发通知。例如,网卡收到了网络包,磁盘完成了IO任务,定时器的间隔时间到了,都可以给CPU发中断信号。 2.CPU之间发送消息:在SMP系统中,一个CPU想要给另一个CPU发送消息,可以给其发送IPI(处理器间中断)。 3.处理CPU异常:CPU在执行指令的过程中遇到了异常会给自己发送中断信号来处理异常。例如,做整数除法运算的时候发现被除数是0,访问虚拟内存的时候发现虚拟内存没有映射到物理内存上。 4.实现系统调用:早期的系统调用就是靠中断指令来实现的,后期虽然开发了专用的系统调用指令,但是其基本原理还是相似的。 1.3 中断的产生 那么中断信号又是如何产生的呢?中断信号的产生有以下4个来源: 1.外设,外设产生的中断信号是异步的,一般也叫做硬件中断(注意硬中断是另外一个概念)。硬件中断按照是否可以屏蔽分为可屏蔽中断和不可屏蔽中断。例如,网卡、磁盘、定时器都可以产生硬件中断。 2.CPU,这里指的是一个CPU向另一个CPU发送中断,这种中断叫做IPI(处理器间中断)。IPI也可以看出是一种特殊的硬件中断,因为它和硬件中断的模式差不多,都是异步的 3.CPU异常,CPU在执行指令的过程中发现异常会向自己发送中断信号,这种中断是同步的,一般也叫做软件中断(注意软中断是另外一个概念)。CPU异常按照是否需要修复以及是否能修复分为3类:1.陷阱(trap),不需要修复,中断处理完成后继续执行下一条指令,2.故障(fault),需要修复也有可能修复,中断处理完成后重新执行之前的指令,3.中止(abort),需要修复但是无法修复,中断处理完成后,进程或者内核将会崩溃。例如,缺页异常是一种故障,所以也叫缺页故障,缺页异常处理完成后会重新执行刚才的指令。 4.中断指令,直接用CPU指令来产生中断信号,这种中断和CPU异常一样是同步的,也可以叫做软件中断。例如,中断指令int 0x80可以用来实现系统调用。 中断信号的4个来源正好对应着中断的4个作用。前两种中断都可以叫做硬件中断,都是异步的;后两种中断都可以叫做软件中断,都是同步的。很多书上也把硬件中断叫做中断,把软件中断叫做异常。 1.4 中断的处理 那么中断信号又是如何处理的呢?也许你会觉得这不是很简单吗,前面的图里面不是画的很清楚吗,中断信号就是在正常的执行流中插入一段中断执行流啊。虽然这种中断处理方式简单又直接,但是它还存在着问题。 执行场景(execute context) 在继续讲解之前,我们先引入一个概念,执行场景(execute context)。在中断产生之前是没有这个概念的,有了中断之后,CPU就分为两个执行场景了,进程执行场景(process context)和中断执行场景(interrupt context)。那么哪些是进程执行场景哪些是中断执行场景呢?进程的执行是进程执行场景,同步中断的处理也是进程执行场景,异步中断的处理是中断执行场景。可能有的人会对同步中断的处理是进程执行场景感到疑惑,但是这也很好理解,因为同步中断处理是和当前指令相关的,可以看做是进程执行的一部分。而异步中断的处理和当前指令没有关系,所以不是进程执行场景。 进程执行场景和中断执行场景有两个区别:一是进程执行场景是可以调度、可以休眠的,而中断执行场景是不可以调度不可用休眠的;二是在进程执行场景中是可以接受中断信号的,而在中断执行场景中是屏蔽中断信号的。所以如果中断执行场景的执行时间太长的话,就会影响我们对新的中断信号的响应性,所以我们需要尽量缩短中断执行场景的时间。为此我们对异步中断的处理有下面两类办法: 1.立即完全处理: 对于简单好处理的异步中断可以立即进行完全处理。 2.立即预处理 + 稍后完全处理: 对于处理起来比较耗时的中断可以采取立即预处理加稍后完全处理的方式来处理。 为了方便表述,我们把立即完全处理和立即预处理都叫做中断预处理,把稍后完全处理叫做中断后处理。中断预处理只有一种实现方式,就是直接处理。但是中断后处理却有很多种方法,其处理方法可以运行在中断执行场景,也可以运行在进程执行场景,前者叫做直接中断后处理,后者叫做线程化中断后处理。 在Linux中,中断预处理叫做上半部,中断后处理叫做下半部。由于“上半部、下半部”词义不明晰,我们在本文中都用中断预处理、中断后处理来称呼。中断预处理只有一种方法,叫做hardirq(硬中断)。中断后处理有很多种方法,分为两类,直接中断后处理有softirq(软中断)、tasklet(微任务),线程化中断后处理有workqueue(工作队列)、threaded_irq(中断线程)。 硬中断、软中断是什么意思呢?本来的异步中断处理是直接把中断处理完的,整个过程是屏蔽中断的,现在,把整个过程分成了两部分,前半部分还是屏蔽中断的,叫做硬中断,处理与硬件相关的紧急事物,后半部分不再屏蔽中断,叫做软中断,处理剩余的事物。由于软中断中不再屏蔽中断信号,所以提高了系统对中断的响应性。 注意硬件中断、软件中断,硬中断、软中断是不同的概念,分别指的是中断的来源和中断的处理方式。 1.5 中断向量号 不同的中断信号需要有不同的处理方式,那么系统是怎么区分不同的中断信号呢?是靠中断向量号。每一个中断信号都有一个中断向量号,中断向量号是一个整数。CPU收到一个中断信号会根据这个信号的中断的向量号去查询中断向量表,根据向量表里面的指示去调用相应的处理函数。 中断信号和中断向量号是如何对应的呢?对于CPU异常来说,其向量号是由CPU架构标准规定的。对于外设来说,其向量号是由设备驱动动态申请的。对于IPI中断和指令中断来说,其向量号是由内核规定的。 那么中断向量表是什么格式,应该如何设置呢,这个我们后面会讲。 1.6 中断框架结构 有了前面这么多基础知识,下面我们对中断机制做个概览。 |
|
|
中断信号的产生有两类,分别是异步中断和同步中断,异步中断包括外设中断和IPI中断,同步中断包括CPU异常和指令中断。无论是同步中断还是异步中断,都要经过中断向量表进行处理。对于同步中断的处理是异常处理或者系统调用,它们都是进程执行场景,所以没有过多的处理方法,就是直接执行。对于异步中断的处理,由于直接调用处理是属于中断执行场景,默认的中断执行场景是会屏蔽中断的,这会降低系统对中断的响应性,所以内核开发出了很多的方法来解决这个问题。 下面的章节是对这个图的详细解释,我们先讲中断向量表,再讲中断的产生,最后讲中断的处理。 本文后面都是以x86 CPU架构进行讲解的。 Linux内核源码学习地址:https://ke.qq.com/course/4032547?flowToken=1041043 【文章福利】小编推荐自己的Linux内核源码分析交流群:【点击1095678385加入】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦! |
|
|
|
|
|
二、中断流程 CPU收到中断信号后会首先保存被中断程序的状态,然后再去执行中断处理程序,最后再返回到原程序中被中断的点去执行。具体是怎么做呢?我们以x86为例讲解一下。 2.1 保存现场 CPU收到中断信号后会首先把一些数据push到内核栈上,保存的数据是和当前执行点相关的,这样中断完成后就可以返回到原执行点。如果CPU当前处于用户态,则会先切换到内核态,把用户栈切换为内核栈再去保存数据(内核栈的位置是在当前线程的TSS中获取的)。下面我们画个图看一下: |

|
|
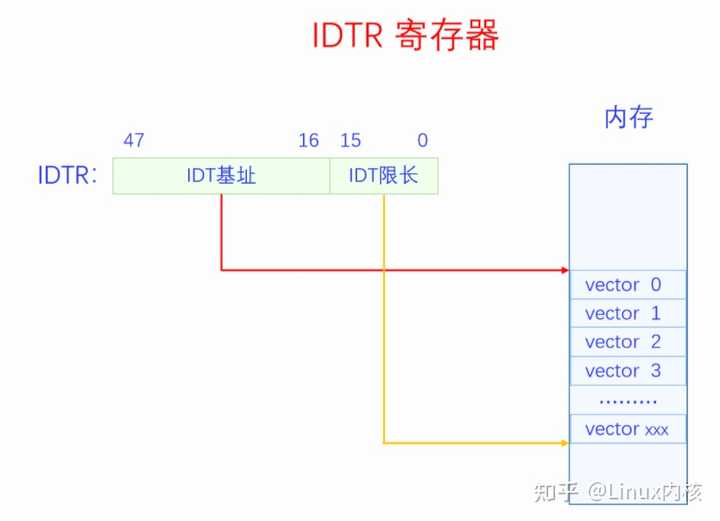
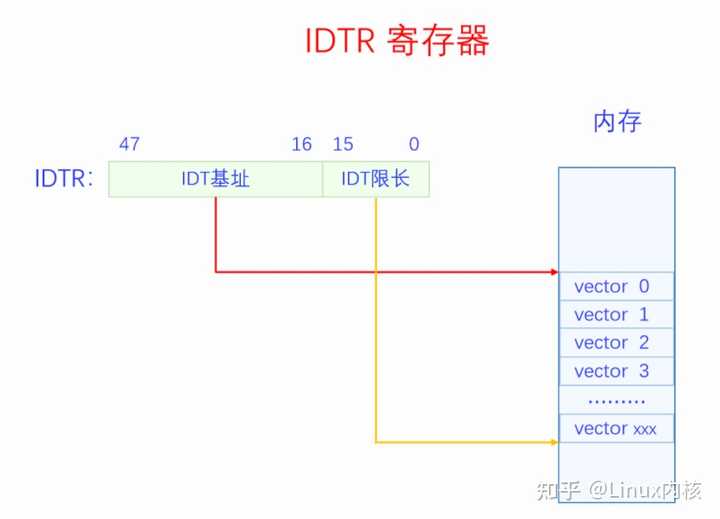
CPU都push了哪些数据呢?分为两种情况。当CPU处于内核态时,会push寄存器EFLAGS、CS、EIP的值到栈上,对于有些CPU异常还会push Error Code。Push CS、EIP是为了中断完成后返回到原执行点,push EFLAGS是为了恢复之前的CPU状态。当CPU处于用户态时,会先切换到内核态,把栈切换到内核栈,然后push寄存器SS(old)、ESP(old)、EFLAGS、CS、EIP的值到新的内核栈,对于有些CPU异常还会push Error Code。Push SS(old)、ESP(old),是为了中断返回的时候可以切换回原来的栈。有些CPU异常会push Error Code,这样可以方便中断处理程序知道更具体的异常信息。不是所有的CPU异常都会push Error Code,具体哪些会哪些不会在3.1节中会讲。 上图是32位的情况,64位的时候会push 64位下的寄存器。 2.2 查找向量表 保存完被中断程序的信息之后,就要去执行中断处理程序了。CPU会根据当前中断信号的向量号去查询中断向量表找到中断处理程序。CPU是如何获得当前中断信号的向量号的呢,如果是CPU异常可以在CPU内部获取,如果是指令中断,在指令中就有向量号,如果是硬件中断,则可以从中断控制器中获取中断向量号。那CPU又是怎么找到中断向量表呢,是通过IDTR寄存器。IDTR寄存器的格式如下图所示: |
|
|
IDTR寄存器由两部分组成:一部分是IDT基地址,在32位上是32位,在64位上是64位,是虚拟内存上的地址;一部分是IDT限长,是16位,单位是字节,代表中断向量表的长度。虽然x86支持256个中断向量,但是系统不一定要用满256个,IDT限长用来指定中断向量表的大小。系统在启动时分配一定大小的内存用来做中断向量表,然后通过LIDT指令设置IDTR寄存器的值,这样CPU就知道中断向量表的位置和大小了。 IDTR寄存器设置好之后,中断向量表的内容还是可以再修改的。该如何修改呢,这就需要我们知道中断向量表的数据结构了。中断向量表是一个数组结构,数组的每一项叫做中断向量表条目,每个条目都是一个门描述符(gate descriptor)。门描述符一共有三种类型,不同类型的具体结构不同,三类门描述符分别是任务门描述符、中断门描述符、陷阱门描述符。任务门不太常用,后面我们都默认忽略任务门。中断门一般用于硬件中断,陷阱门一般用于软件中断。32位下的门描述符是8字节,下面是它们的具体结构: |

|
|
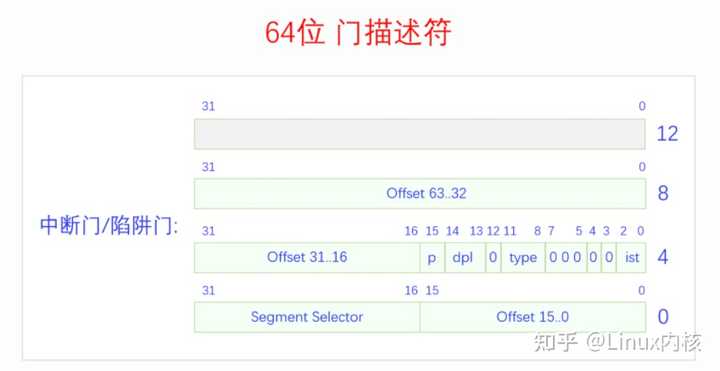
Segment Selector是段选择符,Offset是段偏移,两个段偏移共同构成一个32的段偏移。p代表段是否加载到了内存。dpl是段描述符特权级。d为0代表是16位描述符,d为1代表是32位描述符。Type 是8 9 10三位,代表描述符的类型。 下面看一下64位门描述符的格式: |
|
|
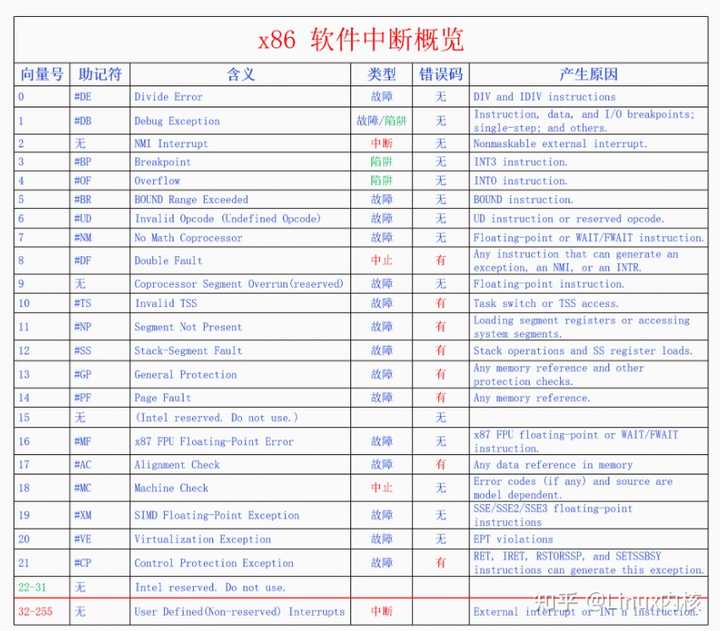
可以看到64位和32位最主要的变化是把段偏移变成了64位。 关于x86的分段机制,这里就不展开讨论了,简介地介绍一下其在Linux内核中的应用。Linux内核并不使用x86的分段机制,但是x86上特权级的切换还是需要用到分段。所以Linux采取的方法是,定义了四个段__KERNEL_CS、__KERNEL_DS、__USER_CS、__USER_DS,这四个段的段基址都是0,段限长都是整个内存大小,所以在逻辑上相当于不分段。但是这四个段的特权级不一样,__KERNEL_CS、__KERNEL_DS是内核特权级,用在内核执行时,__USER_CS、__USER_DS是用户特权级,用在进程执行时。由于中断都运行在内核,所以所有中断的门描述符的段选择符都是__KERNEL_CS,而段偏移实际上就是终端处理函数的虚拟地址。 CPU现在已经把被中断的程序现场保存到内核栈上了,又得到了中断向量号,然后就根据中断向量号从中断向量表中找到对应的门描述符,对描述符做一番安全检查之后,CPU就开始执行中断处理函数(就是门描述符中的段偏移)。中断处理函数的最末尾执行IRET指令,这个指令会根据前面保存在栈上的数据跳回到原来的指令继续执行。 三、软件中断 对中断的基本概念和整个处理流程有了大概的认识之后,我们来看一下软件中断的产生。软件中断有两类,CPU异常和指令中断。我们先来看CPU异常: 3.1 CPU异常 CPU在执行指令的过程中遇到了异常就会给自己发送中断信号。注意异常不一定是错误,只要是异于平常就都是异常。有些异常不但不是错误,它还是实现内核重要功能的方法。CPU异常分为3类:1.陷阱(trap),陷阱并不是错误,而是想要陷入内核来执行一些操作,中断处理完成后继续执行之前的下一条指令,2.故障(fault),故障是程序遇到了问题需要修复,问题不一定是错误,如果问题能够修复,那么中断处理完成后会重新执行之前的指令,如果问题无法修复那就是错误,当前进程将会被杀死。3.中止(abort),系统遇到了很严重的错误,无法修改,一般系统会崩溃。 CPU异常的含义和其向量号都是架构标准提前定义好的,下面我们来看一下。 |
|
|
x86一共有256个中断向量号,前32个(0-31)是Intel预留的,其中0-21(除了15)都已分配给特定的CPU异常。32-255是给硬件中断和指令中断保留的向量号。 3.2 指令中断 指令中断和CPU异常有很大的相似性,都属于同步中断,都是属于因为执行指令而产生了中断。不同的是CPU异常不是在执行特定的指令时发生的,也不是必然发生。而指令中断是执行特定的指令而发生的中断,设计这些指令的目的就是为了产生中断的,而且一定会产生中断或者有些条件成立的情况下一定会产生中断。其中指令INT n可以产生任意中断,n可以取任意值。Linux用int 0x80来作为系统调用的指令。关于系统调用的详细情况 四、硬件中断 硬件中断分为外设中断和处理器间中断(IPI),下面我们先来看一下外设中断。 4.1 外设中断 外设中断和软件中断有一个很大的不同,软件中断是CPU自己给自己发送中断,而外设中断是需要外设发送中断给CPU。外设想要给CPU发送中断,那就必须要连接到CPU,不可能隔空发送。那么怎么连接呢,如果所有外设都直接连到CPU,显然是不可能的。因为一个计算机系统中的外设是非常多的,而且多种多样,CPU无法提前为所有外设设计和预留接口。所以需要一个中间设备,就像秘书一样替CPU连接到所有的外设并接收中断信号,再转发给CPU,这个设备就叫做中断控制器(Interrupt Controller )。 在x86上,在UP时代的时候,有一个中断控制器叫做PIC(Programmable Interrupt Controller )。所有的外设都连接到PIC上,PIC再连接到CPU的中断引脚上。外设给PIC发中断,PIC再把中断转发给CPU。由于PIC的设计问题,一个PIC只能连接8个外设,所以后来把两个PIC级联起来,第二个PIC连接到第一个PIC的一个引脚上,这样一共能连接15个外设。 到了SMP时代的时候,PIC显然不能胜任工作了,于是Intel开发了APIC(Advanced PIC)。APIC分为两个部分:一部分是Local APIC,有NR_CPU个,每个CPU都连接一个Local APIC;一部分是IO APIC,只有一个,所有的外设都连接到这个IO APIC上。IO APIC连接到所有的Local APIC上,当外设向IO APIC发送中断时,IO APIC会把中断信号转发给某个Local APIC。有些per CPU的设备是直接连接到Local APIC的,可以通过Local APIC直接给自己的CPU发送中断。 外设中断并不是直接分配中断向量号,而是直接分配IRQ号,然后IRQ+32就是其中断向量号。有些外设的IRQ是内核预先设定好的,有些是行业默认的IRQ号。 关于APIC的细节这里就不再阐述了,推荐大家去看《Interrupt in Linux (硬件篇)》,对APIC讲的比较详细。 4.2 处理器间中断 在SMP系统中,多个CPU之间有时候也需要发送消息,于是就产生了处理器间中断(IPI)。IPI既像软件中断又像硬件中断,它的产生像软件中断,是在程序中用代码发送的,而它的处理像硬件中断,是异步的。我们这里把IPI看作是硬件中断,因为一个CPU可以把另外一个CPU看做外设,就相当于是外设发来的中断。 五、中断处理 终于讲到中断处理了,我们再把之前的中间机制图搬过来,再回顾一下: |
|
|
无论是硬件中断还是软件中断,都是通过中断向量表进行处理的。但是不同的是,软件中断的处理程序是属于进程执行场景,所以直接把中断处理程序设置好就行了,中断处理程序怎么写也没有什么要顾虑的。而硬件中断的处理程序就不同了,它是属于中断执行场景。不仅其中断处理函数中不能调用会阻塞、休眠的函数,而且处理程序本身要尽量的短,越短越好。所以为了使硬件中断处理函数尽可能的短,Linux内核开发了一大堆方法。这些方法包括硬中断(hardirq)、软中断(softirq)、微任务(tasklet)、中断线程(threaded irq)、工作队列(workqueue)。其实硬中断严格来说不算是一种方法,因为它是中断处理的必经之路,它就是中断向量表里面设置的处理函数。为了和软中断进行区分,才把硬中断叫做硬中断。硬中断和软中断都是属于中断执行场景,而中断线程和工作队列是属于进程执行场景。把硬件中断的处理任务放到进程场景里面来做,大大提高了中断处理的灵活性。 由于软件中断的处理都是直接处理,都是内核本身直接写好了的,一般都接触不到,而硬件中断的处理和硬件驱动密切相关,所以很多书上所讲的中断处理都是指的硬件中断的处理。 5.1 异常处理 x86上的异常处理是怎么设置的呢?我们把前面的图搬过来看一下: |
|
|
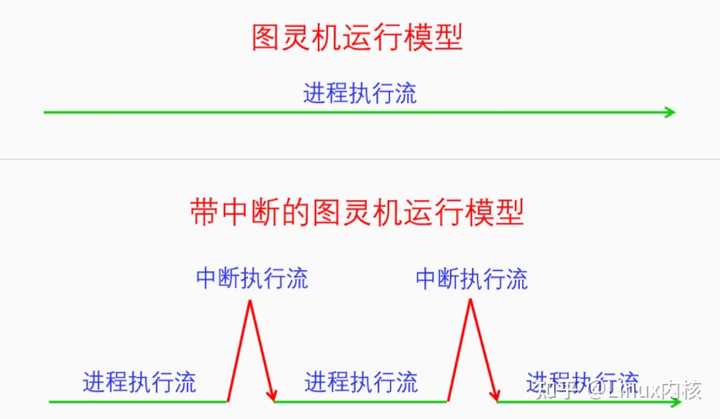
我们对照着这个图去捋代码。首先我们需要分配一片内存来存放中断向量表,这个是在如下代码中分配的。 linux-src/arch/x86/kernel/idt.c linux-src/arch/x86/include/asm/desc_defs.h linux-src/arch/x86/include/asm/segment.h 可以看到我们的中断向量表idt_table是门描述符gate_desc的数组,数组大小是IDT_ENTRIES 256。门描述符gate_desc的定义和前面画的图是一致的,注意x86是小端序。 寄存器IDTR内容包括IDT的基址和限长,为此我们专门定义一个数据结构包含IDT的基址和限长,然后就可以用这个变量通过LIDT指令来设置IDTR寄存器了。 linux-src/arch/x86/kernel/idt.c linux-src/arch/x86/include/asm/desc.h 有一点需要注意的,我们并不是需要把idt_table完全初始化好了再去load_idt,我们可以先初始化一部分的idt_table,然后再去load_idt,之后可以不停地去完善idt_table。 我们先来看一下内核是什么时候load_idt的,其实内核有多次load_idt,不过实际上只需要一次就够了。 调用栈如下: start_kernel setup_arch idt_setup_early_traps 代码如下: linux-src/arch/x86/kernel/idt.c 这是内核在start_kernel里第一次设置IDTR,虽然之前的代码里也有设置过IDTR,我们就不考虑了。load_idt之后,IDT就生效了,只不过这里IDT还没有设置全,只设置了少数几个CPU异常的处理函数,我们来看一下是怎么设置的。 linux-src/arch/x86/kernel/idt.c 在函数idt_setup_from_table里会定义一个gate_desc的临时变量,然后用idt_data来初始化这个gate_desc,最后会把gate_desc复制到idt_table中对应的位置中去。这样中断向量表中的这一项就生效了。 下面我们再来看看idt_data数据是怎么来的: linux-src/arch/x86/kernel/idt.c linux-src/arch/x86/kernel/traps.c early_idts是idt_data的数组,在这里定义了两个中断向量表的条目,分别是X86_TRAP_DB和X86_TRAP_BP,它们的中断处理函数分别是asm_exc_debug和asm_exc_int3。这里只是设置了两个中断向量表条目,并且把IDTR寄存器设置好了,后来就不需要再设置IDTR寄存器了。 下面我们看一下所有CPU异常的处理函数是怎么设置的。 先看调用栈: start_kernel trap_init idt_setup_traps 代码如下: linux-src/arch/x86/kernel/idt.c 可以看到这次设置非常简单,就是调用了一下idt_setup_from_table,并没有调用load_idt。主要是数组def_idts里面包含了大部分的CPU异常处理。但是没缺页异常,缺页异常是单独设置。设置路径如下: 调用栈: start_kernel setup_arch idt_setup_early_pf 代码如下: linux-src/arch/x86/kernel/idt.c 5.2 硬中断(hardirq) 硬件中断的中断处理和软件中断有一部分是相同的,有一部分却有很大的不同。对于IPI中断和per CPU中断,其设置是和软件中断相同的,都是一步到位设置到具体的处理函数。但是对于余下的外设中断,只是设置了入口函数,并没有设置具体的处理函数,而且是所有的外设中断的处理函数都统一到了同一个入口函数。然后在这个入口函数处会调用相应的irq描述符的handler函数,这个handler函数是中断控制器设置的。中断控制器设置的这个handler函数会处理与这个中断控制器相关的一些事物,然后再调用具体设备注册的irqaction的handler函数进行具体的中断处理。 我们先来看一下对中断向量表条目的设置代码。 调用栈如下: start_kernel init_IRQ native_init_IRQ idt_setup_apic_and_irq_gates 代码如下: linux-src/arch/x86/kernel/idt.c linux-src/arch/x86/include/asm/desc.h linux-src/arch/x86/include/asm/idtentry.h linux-src/arch/x86/kernel/irq.c linux-src/arch/x86/kernel/irqinit.c linux-src/arch/x86/include/asm/hw_irq.h linux-src/include/linux/irqdesc.h 从上面的代码可以看出,对硬件中断的设置分为两个部分,一部分就像前面的软件中断的方式一样,是从apic_idts数组设置的,设置的都是一些IPI和per CPU的中断。另一部分是把所有剩余的硬件中断的处理函数都设置为irq_entries_start,irq_entries_start会调用common_interrupt函数。在common_interrupt函数中会根据中断向量号去读取per CPU的数组变量vector_irq,得到一个irq_desc。最终会调用irq_desc中的handle_irq来处理这个中断。 对于外设中断为什么要采取这样的处理方式呢?有两个原因,1是因为外设中断和中断控制器相关联,这样可以统一处理与中断控制器相关的事物,2是因为外设中断的驱动执行比较晚,有些设备还是可以热插拔的,直接把它们放到中断向量表上比较麻烦。有个irq_desc这个中间层,设备驱动后面只需要调用函数request_irq来注册ISR,只处理与设备相关的业务就可以了,而不用考虑和中断控制器硬件相关的处理。 我们先来看一下vector_irq数组是怎么初始化的。 linux-src/arch/x86/kernel/apic/vector.c linux-src/kernel/irq/irqdesc.c 可以看出vector_irq数组的初始化数据是从irq_desc_tree来的,我们再来看一下irq_desc_tree是怎么初始化的。 linux-src/kernel/irq/irqdesc.c 可以看到vector_irq数组的内容是在系统初始化的时候通过alloc_desc函数为每个irq进行分配的。在alloc_desc中对irq_desc的初始化会把handle_irq函数指针默认初始化为handle_bad_irq,这个函数代表还没有中断控制器注册这个函数,handle_bad_irq只是简单地确认一下中断,然后做个错误记录。 中断控制器注册handle_irq函数的代码如下: linux-src/kernel/irq/chip.c 不同的系统有不同的中断控制器,其在启动初始化的时候都会去注册irq_desc的handle_irq函数。 下面我们再来看一下具体的硬件驱动应该如何注册自己设备的ISR: linux-src/include/linux/interrupt.h linux-src/kernel/irq/manage.c 驱动程序使用request_irq接口来注册自己的ISR,ISR就是运行在硬中断的,参数handler代表的就是ISR。request_irq又调用request_threaded_irq来实现自己。request_threaded_irq是用来创建中断线程的函数接口,其中有两个参数handler、thread_fn,都是函数指针,handler代表的是ISR,是进行中断预处理的,thread_fn代表的是要创建的中断线程的入口函数,是进行中断后处理的。中断线程的细节我们在5.5中断线程中再细讲。 我们再来总结一下外设中断的处理方式。外设中断的向量表条目都被统一设置到同一个函数common_interrupt。在函数common_interrupt中又会根据irq参数去一个类型为irq_desc的vector_irq数组中寻找其对应的irq_desc,并用irq_desc的handle_irq来处理这个中断。vector_irq数组是在系统启动时初始化的,每个irq_desc的handle_irq都是中断控制器初始化时设置的,handle_irq的处理是和中断控制器密切相关的。具体的硬件驱动会通过request_irq接口来注册ISR,每个ISR都会生成一个irqaction,这个irqaction会挂在irq_desc的链表上。这样中断发生时handle_irq就可以去执行与irq相对应的每个ISR了。 5.3 软中断(softirq) 软中断是把中断处理程序分成了两段:前一段叫做硬中断,执行驱动的ISR,处理与硬件密切相关的事,在此期间是禁止中断的;后一段叫做软中断,软中断中处理和硬件不太密切的事物,在此期间是开中断的,可以继续接受硬件中断。软中断的设计提高了系统对中断的响应性。下面我们先说软中断的执行时机,然后再说软中断的使用接口。 软中断也是中断处理程序的一部分,是在ISR执行完成之后运行的,在ISR中可以向软中断中添加任务,然后软中断有事要做就会运行了。有些时候当软中断过多,处理不过来的时候,也会唤醒ksoftirqd/x线程来执行软中断。 linux-src/kernel/irq/irqdesc.c linux-src/kernel/softirq.c 可以看到__do_softirq在执行软中断前会打开中断local_irq_enable(),在执行完软中断之后又会关闭中断local_irq_disable()。所以软中断执行期间CPU是可以接收硬件中断的。 下面我们再来看一下软中断的使用接口。软中断定义了一个softirq_action类型的数组,数组大小是NR_SOFTIRQS,代表软中断的类型,目前只有10种软中断类型。softirq_action结构体里面仅仅只有一个函数指针。当我们要设置某一类软中断的处理函数时使用接口open_softirq。当我们想要触发某一类软中断的执行时使用接口raise_softirq。 下面我们来看一下代码: linux-src/include/linux/interrupt.h linux-src/kernel/softirq.c 所有软中断的处理函数都是在系统启动的初始化函数里面用open_softirq接口设置的。raise_softirq一般是在硬中断或者软中断中用来往软中断上push work使得软中断可以被触发执行或者继续执行。 5.4 微任务(tasklet) 新代码要想使用softirq就必须修改内核的核心代码,添加新的softirq类型,这对于很多驱动程序来说是做不到的,于是内核在softirq的基础上开发了tasklet。使用tasklet不需要修改内核的核心代码,驱动程序直接使用tasklet的接口就可以了。 Tasklet其实是一种特殊的softirq,它是在softirq的基础上进行了扩展。它利用的就是softirq中的HI_SOFTIRQ和TASKLET_SOFTIRQ。softirq在初始化的时候会设置这两个softirq类型。然后其处理函数会去处理tasklet的链表。我们在使用tasklet的时候只需要定义一个tasklet_struct,并用我们想要执行的函数初始化它,然后再用tasklet_schedule把它放入到队列中,它就会被执行了。下面我们来看一下代码: linux-src/kernel/softirq.c linux-src/include/linux/interrupt.h Tasklet和softirq有一个很大的区别就是,同一个softirq可以在不同的CPU上并发执行,而同一个tasklet不会在多个CPU上并发执行。所以我们在编程的时候,如果使用的是tasklet就不用考虑多CPU之间的同步问题。 还有很重要的一点,tasklet不是独立的,它是softirq的一部分,禁用软中断的同时也禁用了tasklet。 5.5 中断线程(threaded_irq) 前面讲的硬中断,它是外设中断处理中必不可少的一部分。Softirq和tasklet虽然不会禁用中断,提高了系统对中断的响应性,但是softirq的执行优先级还是比进程的优先级高,有些确实不那么重要的任务其实可以放到进程里执行,和普通进程共同竞争CPU。而且软中断里不能调用会阻塞、休眠的函数,这对软中断函数的编程是很不利的,所以综合各种因素,我们需要把中断处理任务中的与硬件无关有不太紧急的部分放到进程里面来做。为此内核开发了两种方法,中断线程和工作队列。 我们这节先讲中断线程,其接口如下: linux-src/include/linux/interrupt.h 如果我们要为某个外设注册中断处理程序,可以使用这个接口。其中handler是硬中断,是处理与硬件密切相关的事物。其处理完成后,可以把接收到的数据、要继续处理的事情放到某个位置,然后返回是否需要唤醒对应的中断线程。如果需要的话,系统会唤醒其对应的中断线程来继续处理任务,这个线程的主函数就是第三个参数thread_fn。下面我们来看一下这个接口的实现。 linux-src/kernel/irq/manage.c 中断线程虽然实现很复杂,但是其使用接口还是很简单的。 5.6 工作队列(workqueue) 工作队列是内核中使用最广泛的线程化中断处理机制。系统中有一些默认的工作队列,你也可以创建自己的工作队列,工作队列背后对应的是内核线程。你可以创建一个work,然后push到某个工作队列,然后这个工作队列背后的内核线程就会去执行这些work。下面我们来看一下工作队列的接口。 这是创建work,把work push到系统默认的工作队列上的接口,下面我们再来看一下创建自己的工作队列的接口: linux-src/include/linux/workqueue.h 工作队列还有很多很丰富的接口,这里就不一一介绍了。 关于工作队列的实现原理,推荐阅读: Concurrency Managed Workqueue之(一):workqueue的基本概念 Concurrency Managed Workqueue之(二):CMWQ概述 Concurrency Managed Workqueue之(三):创建workqueue代码分析 Concurrency Managed Workqueue之(四):workqueue如何处理work 六、中断与同步 在只有线程的情况下,线程之间的同步逻辑还是很好理解的,但是有了中断之后,硬中断、软中断、线程相互之间的同步就变得复杂起来。下面我们就来看一下它们在运行的时候相互之间的抢占关系。 6.1 CPU运行模型 首先我们来看一下CPU最原始的运行模型,图灵机模型,非常简单,就是一条直线一直运行下去。 |
|
|
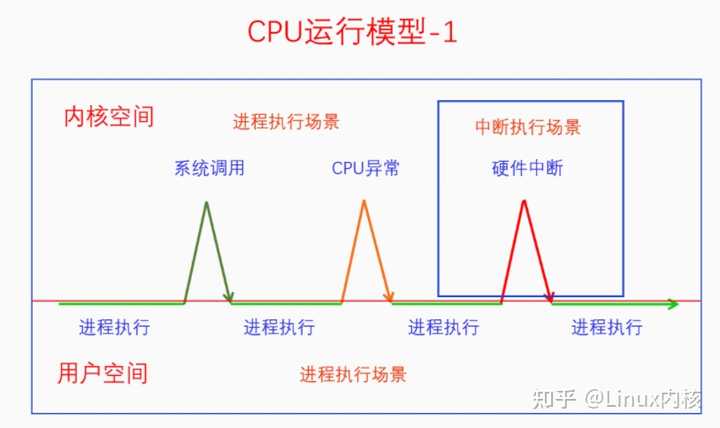
在图灵机上加入中断之后,CPU的运行模型也是比较简单的。但是当我们考虑软件中断、硬件中断的区别时,CPU运行模型就开始变得复杂起来了。 |
|
|
不同的中断类型使得中断执行流有了不同的类型,这里一共分为三种类型,系统调用、CPU异常、硬件中断。现在这个还不算复杂,下面我们看一下它们之间的抢占情形。 |
|
|
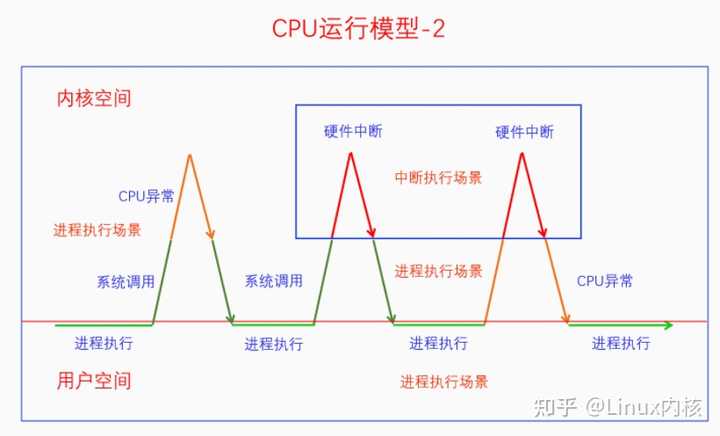
在系统调用时会发生CPU异常,也可能会发生硬件中断,在CPU异常的时候也可能发生硬件中断。其实这三者也可以嵌套起来,请看下图: |
|
|
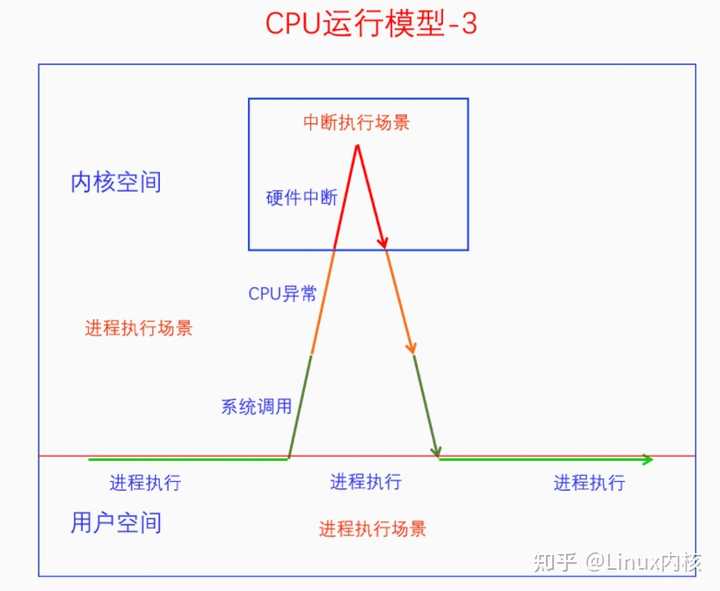
系统调用时发生了CPU异常,CPU异常时发生了硬件中断。下面我们把硬件中断的处理过程分为硬中断和软中断两部分,看看它们之间的关系。 |
|
|
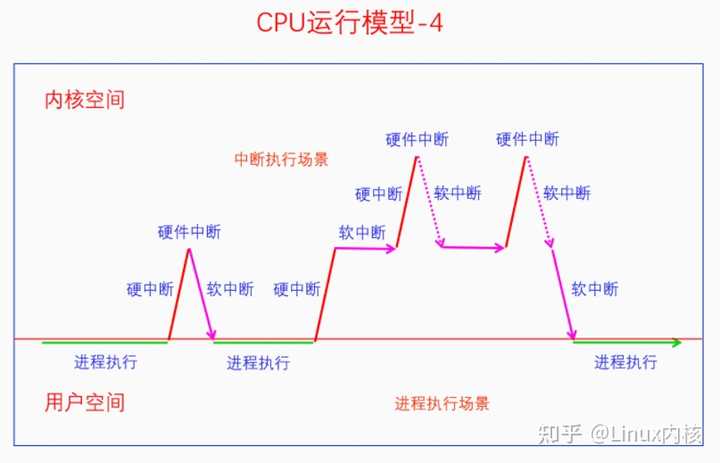
硬件中断的前半部分是硬中断,后半部分是软中断,硬中断中不能再嵌套硬中断了,但是软中断中可以嵌套硬中断。不过嵌套的硬中断在返回时发现正在执行软中断,就不会再重新还行软中断了,而是会回到原来的软中断执行流中。软中断的执行还有一种情况,如下图所示: |
|
|
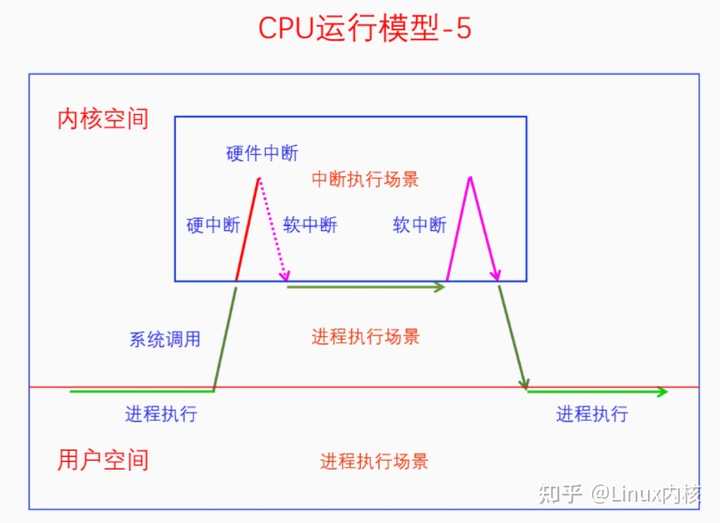
这是因为线程在其临界区中禁用了软中断,如果临界区中发生了硬中断还是会执行的,但是硬中断返回时不会去执行软中断,因为软中断被禁用了。当线程的临界区结束是会再打开软中断,此时发现有pending的软中断没有处理,就会去执行软中断。 还有一种比较特殊的情况,就是线程里套软中断,软中断里套硬中断,硬中断里套NMI中断,如下图所示: |
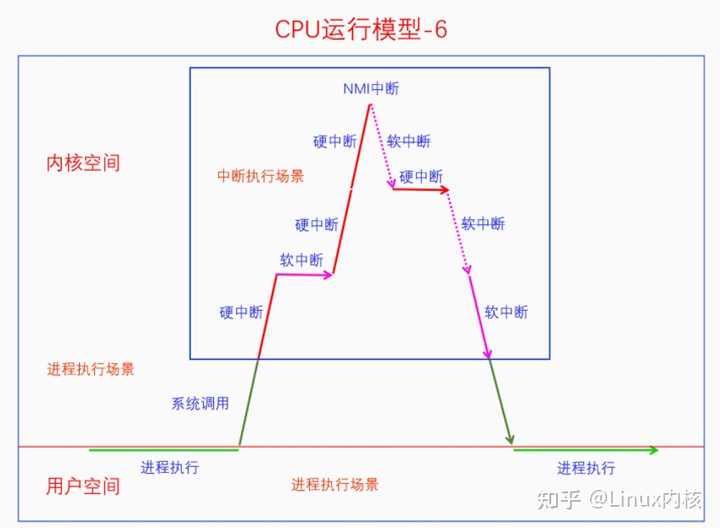
|
|
首先软中断是不能独立触发的,必须是硬中断触发软中断。在图中,第一个硬中断是执行完成了的,然后在软中断的执行过程中又发生了硬中断,第二个硬中断还没执行完的时候在执行过程中的时候又发生了NMI中断。这样就发生了四个不同等级的执行流一一嵌套的情况,这也是队列自旋锁的锁节点为啥要乘以4的原因。 6.2 中断相关同步方法 软中断可以抢占线程,硬中断可以抢占软中断也可以抢占线程,而返回来则不能抢占,所以如果我们的低等级执行流代码和高等级执行流代码有同步问题的话,就要考虑禁用高等级执行流。下面我们来看一下它们的接口,首先看禁用硬中断: linux-src/include/linux/irqflags.h linux-src/include/linux/interrupt.h 你可以在一个CPU上禁用所有中断,也可以在所有CPU上禁用某个硬件中断,但是你不能在所有CPU上同时禁用所有硬件中断。 再来看一下禁用软中断的接口: linux-src/include/linux/bottom_half.h 我们只能禁用本地CPU的软中断,而且是整体禁用,不能只禁用某一类型的软中断。虽然在Linux中,下半部bh包括所有的下半部,但是此处的bh仅仅指软中断(包括tasklet),不包括中断线程和工作队列。 七、总结回顾 本文我们从中断的概念开始讲起,一路上分析了中断的作用、中断的产生、中断的处理。其中内容最多的是硬件中断的处理,方法很多很繁杂。从6.1节CPU运行模型中,我们可以看到中断对于推动整个系统运行的重要性。所以说中断机制是计算机系统的神经和脉搏,一点都不为过。想要学会Linux内核,弄明白中断机制是其中必不可少的一环。最后我们再来看一下中断机制的图: |
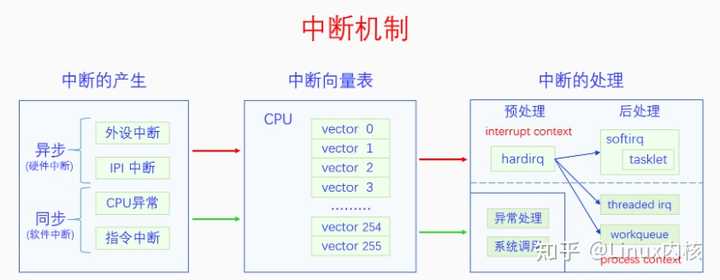
|
|
参考文献: 《Linux Kernel Development》 《Understanding the Linux Kernel》 《Professional Linux Kernel Architecture》 《Intel? 64 and IA-32 Architectures Software Developer’s Manual Volume 3》 《Interrupt in Linux (硬件篇)》 原文链接:深入理解Linux中断机制_城中之城的博客-CSDN博客_linux中断流程 |
|
中断绝对不是硬件代替软件去轮询,而是硬件的结构决定了,当那个管脚电平变低(或者变高)的时候,cpu就会被打断,并从特定地址开始执行。就像cpu的reset被拉低的时候一定会复位并从0地址(当然,不一定是0地址,具体看什么芯片了)开始执行一样,都是硬件的结构决定的。 |
|
特tm讨厌“本质”这个烂词。“中断”就是中断,没别的意思,就是“中断”了cpu指令的运行。和某些答主说的软件里的“事件”从概念上是有区别的,interupt是真正打断了cpu指令执行的连续性。是通过控制总线产生的而非cpu轮询。计算机cpu靠周期电脉冲运行指令,通俗的理解就是个死循环,不停地执行下去。但是要让他和外界互动,就需要打断这个循环,这个打断过程的东西,就是“中断”,比如用户的输入,敲一下键盘,或是设备的通知,比如磁盘读完了一段数据,都是中断。cpu在收到了中断之后,指令按中断分类,再根据中断的类型决定下一步的指令。 你要深究那就理论就多了,我这里只是通俗的解释。涉及到冯诺依曼体系架构了,中断就是控制总线的一些电信号。 |
|
很专业的问题,简单答一下。 题主的理解部分正确,但中断与轮询在本质上是不同的概念。中断机制允许CPU在执行程序时,响应外部或内部事件,而轮询则是一种主动检查机制。 一 中断的本质 1. 异步事件响应:中断是一种异步事件处理机制。当外部设备(键盘、鼠标、磁盘控制器等)需要CPU注意时,它会发送一个中断信号给中断控制器,中断控制器再将这个信号转发给CPU,CPU拿到信号后再做进一步处理。这种机制允许CPU在执行当前任务的同时,能够及时响应这些外部事件。 2. 硬件实现:中断信号通过硬件线路直接传递给CPU,而不是通过软件查询。大多数现代CPU都有专门的中断引脚,当这些引脚上出现信号时,CPU立即响应。 3. 上下文切换:当CPU接收到中断信号时,会暂停当前正在执行的任务,保存当前的上下文(程序计数器、寄存器状态等),然后跳转到预先定义的中断服务例程(Interrupt Service Routine,简称 ISR)去处理中断。处理完中断后,CPU会恢复之前保存的上下文,并继续执行被中断的任务。 |
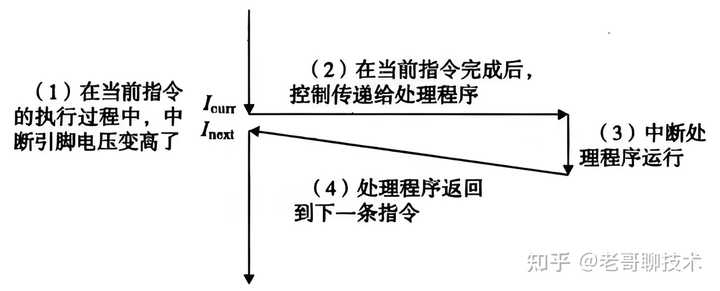
|
|
Interrupt二 中断与轮询的区别 中断:是被动式的,只有在有事件发生时才会响应。这减少了CPU的负载,因为它不需要不断地检查是否有事件发生。 轮询:是主动式的,需要CPU不断地检查设备状态。这种方法效率较低,因为它会占用CPU资源,即使没有事件发生。 举个例子 说下常见的电脑键盘输入。当我们按键时,键盘控制器会产生一个中断信号。如果没有中断机制,CPU需要不断地轮询键盘控制器,来检查是否有键被按下。这不仅效率低下,而且会导致CPU资源的浪费。 而有了中断机制,CPU在接收到中断信号后,可以立即暂停当前任务,跳转到键盘输入的中断服务例程上,处理按键事件。处理完毕后,CPU恢复之前的任务,继续执行。这样,CPU的效率得到了极大的提升,同时也保证了对外部事件的及时响应。 |
|
|
Polling三 总结 中断的本质是一种硬件实现的异步事件处理机制。中断允许CPU在执行程序的同时,响应外部或内部事件。与轮询不同,中断是被动式的,只有在事件发生时才会响应,从而提高了CPU的效率和响应速度。 |
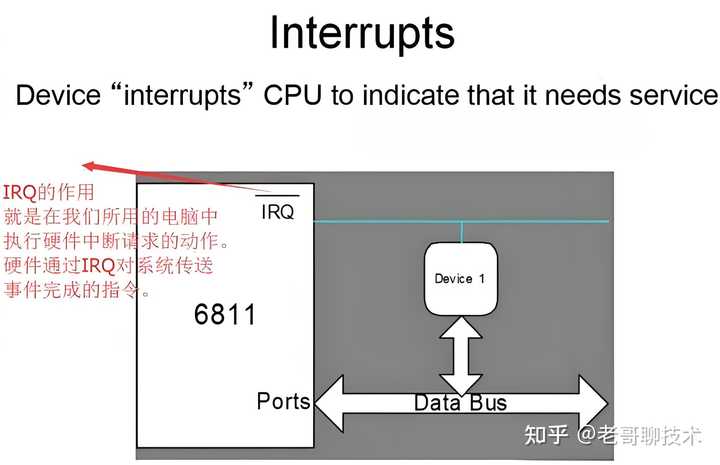
|
|
以上,完。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
计算机启动时,bootloader或者操作系统和cpu做了一个约定:cpu发生第N号中断时,让某一个cpu的指令寄存器切换为某个值,N这个值则存放在另外一个寄存器里。这里中断就是一个逻辑概念。 cpu 则通过data sheet白皮书手册和主板芯片做一个约定:在cpu的某个引脚产生特定的电平信号,cpu就可以产生第N号中断。这里中断就和物理事件搭上了线。 主板则再通过说明书和外部设备做一个约定:通过主板某接口产生特定的电平信号,主板就可以向cpu发起第N号中断。这样中断就和外部设备发生了需要cpu进行处理的事件 搭上了线。 当然,很多廉价嵌入式设备和体积精简的手机是没有主板这一层的,那么硬件驱动程序就必须按照实际的硬件电路板的接线方式来进行中断处理。当然实际往往多数操作系统提供板级开发包 board support package 来辅助厂商完成这部分功能(从某种程度上来说实现了一种“软主板”)。 总体而言:中断就是一种外设访问cpu的调用约定(怎么把通知参数通过电平信号和引脚传递),类似应用程序的函数调用约定(怎么把参数通过内存或cpu寄存器传递)。从流程来讲,更类似于应用程序的回调函数的调用,操作系统内核负责注册(中断处理)函数地址,外层的cpu又对外承诺如何产生中断处理的函数参数,这样外设就可以向cpu产生函数回调了。 送礼物 还没有人送礼物,鼓励一下作者吧 |
|
|
| [收藏本文] 【下载本文】 |
| 科技知识 最新文章 |
| 百度为什么越来越垃圾了? |
| 百度为什么越来越垃圾了? |
| 为什么程序员总是发现不了自己的Bug? |
| 出现在抖音评论区里边的算命真不真? |
| 你认为 C++ 最不应该存在的特性是什么? |
| 为什么 Windows 的兼容性这么强大,到底用了 |
| 如何看待Nvidia禁止使用翻译工具将cuda运行 |
| 为何苹果搞了十年的汽车还是难产,小米很快 |
| 该不该和AI说谢谢? |
| 为什么突破性的技术总是最先发生在西方? |
| 上一篇文章 下一篇文章 查看所有文章 |
|
|
|
| 股票涨跌实时统计 涨停板选股 分时图选股 跌停板选股 K线图选股 成交量选股 均线选股 趋势线选股 筹码理论 波浪理论 缠论 MACD指标 KDJ指标 BOLL指标 RSI指标 炒股基础知识 炒股故事 |
| 网站联系: qq:121756557 email:121756557@qq.com 天天财汇 |