
| |
|
|
| ����ƻ� -> �Ƽ�֪ʶ -> ����������Щ���������٣�����ţ�ƺܾ�����㷨����Ŀ������ -> �����Ķ� |
|
|
[�Ƽ�֪ʶ]����������Щ���������٣�����ţ�ƺܾ�����㷨����Ŀ������ |
| [�ղر���] �����ر��ġ� |
|
�Dz��Ǵ���Խ��Խ�ã���ʲô������������̸�λ�������� |
|
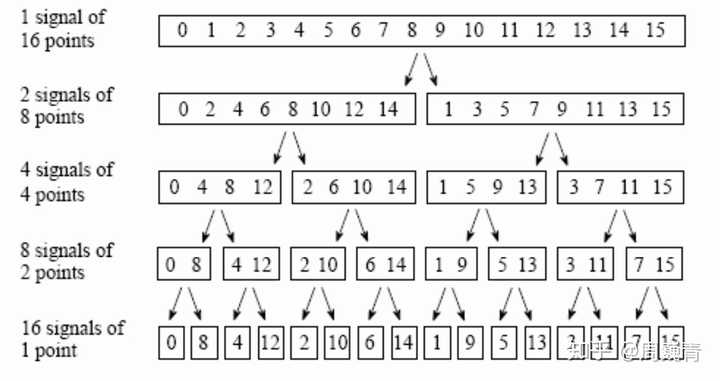
���ٸ���Ҷ�任��FFT���������㷨�õݹ鷨��ʮ�и㶨�� �����Ӧ����Ϊ��Ҫ���㷨֮һ���㷺Ӧ���ڸ��ָ����Ĺ�ҵ�Ϳ�ѧʵ���С���һ�ο����ݹ�������ٸ���Ҷ��ʱ���˺ܾá�����������ѧ�ҵĺܶ�Ŭ�����������㷨�����Ӷȴ�N^2������N*log(N)�����ÿ��Գ�֮Ϊ�����ǻ۵ľ����ˡ� �пտ�������Դ���롣 2020.1.15 �⼸��æ�ſ��У���ұ�����һ����հ��㷨��Դ������������ ��һ�θ��£�1.15���� ������֪����ѧ����һ������Ҷ�任���ǽ�������ʵ�ռ�Ķ�����任�����ռ�Ķ������ϣ�����任�dz���Ҫ����ΪһЩʵ�ռ䲻���ֵ���Ϣ���ڵ��ռ��л���ֵķdz����ԣ����Ը���Ҷ�任�Ǻܶ��źš������ķ���������������ʽ���£� H(f)=\int_{-\infty}^{\infty}h(t)e^{-2\pi ift}dt �Լ�����任�� h(t)=\int_{-\infty}^{\infty}H(f)e^{2\pi ift}df ��������ڼ������Ҫ���ʵ�ָ���Ҷ�任��Ҫ���ɱ���������������ƣ���һ����ʵ�������������ֵ����½����쵽�����������һ����һ���н���֣��ڶ�������ʲô�����Ĺ�ʽ��ֻҪ����Ҫ�������ʵ�֣��ͱ��������ɢ��������������������֣� \int ���ͽ���Ϊ��ɢ��ͣ� \sum �������������������ؽ����µģ�������ν�ġ���ɢ����Ҷ�任����Discrete Fourier Transform�����DFT����������ʽҲ��ֱ�ۣ� H(f)=\int_{-\infty}^{\infty}h(t)e^{-2\pi ift}dt\approx\sum_{k=0}^{N-1}h_{k}e^{-2\pi if_{n}t_{k}}\Delta ���������ʵ���������DFT�ر�̣���ʵ�Ѿ�����ʵ�ָ���Ҷ�任�ˡ���������Ϊʲô��������㷨�أ�����Ϊ���Ӷȡ� ���Ӷ����㷨�е�һ���������˵���Ǹ��Ӷ�Խ�ߣ���ô����㷨�������ϵ��Խ���ѣ����ж������أ��Ҿٸ����ӣ������㷨�������ж��ھ���ĶԽǻ�Ӧ�������������Ҫ���ˣ�����ĶԽǻ��ļ��㸴�Ӷ��� O(N^{3}) ������˵�Խǻ���ʱ������ž���ά�������η����ӣ�����ʮ�ֲֿ���������Ŀǰ�����ͨ�õĶԽǻ��⣬���� lapcak���Խǻ��ļ���ά��һ��Ҳ���� 10000, �����������DFT�ĸ��Ӷ��Ƕ����أ�����Դӹ�ʽ�Ͽ��������������Ҫ��һ������N�������������DFT������ÿ������һ���任���������Ҫ����N�ε����㣬������㷨�ĸ��Ӷ�Ҳ���� O(N2)" role="presentation">O(N2)O(N^{2}) ��Ҳ����˵����DFT���Ҳ��ֻ�ܴ������һ��ӵ�д�� 106∼ 107" role="presentation">106�� 10710^{6}\sim~10^{7} ���������顣��������������ʵ���У���ʵ�ڲ���һ��������ޣ�����������Ӷȵ�Ӳ��һֱ��Լ��DFT�ķ�չ������������ڵ�ʱ��Լ�����������������ġ������ӡ������⣬���FFTû�г��֣������ǵ��������ھ��Բ�������������ӡ� ʱ������1965�꣬James Cooley �� John Tukey ������һ���㷨�����ֵ��㷨�ĸ��ӶȽ���Ϊ�� N×log2(N)" role="presentation">N��log2(N)N \times log_{2}(N) ���������㷨�ͳ�֮Ϊ�����ٸ���Ҷ�任����Fast Fourier transform�� ���FFT��������ʵ����������⣬Danielson �� Lanczos ��1942����Ѿ���ʼ����ص����ۡ����Ƿ����κ�һ��DFT��ʵ�������¸�д������DFT�ĺͣ� Fk=∑j=0N−1e2πijk/Nfj=∑j=0N/2−1e2πik(2j)/Nf2j+∑j=0N/2−1e2πik(2j+1)/Nf2j+1=∑j=0N/2−1e2πikj/(N/2)f2j+Wk∑j=0N/2−1e2πikj/(N/2)f2j+1=Fke+WkFko" role="presentation">Fk=��j=0N?1e2��ijk/Nfj=��j=0N/2?1e2��ik(2j)/Nf2j+��j=0N/2?1e2��ik(2j+1)/Nf2j+1=��j=0N/2?1e2��ikj/(N/2)f2j+Wk��j=0N/2?1e2��ikj/(N/2)f2j+1=Fke+WkFko\begin{split} F_{k}&=\sum_{j=0}^{N-1}e^{2\pi ijk/N}f_{j}\\ &=\sum_{j=0}^{N/2-1}e^{2\pi ik(2j)/N}f_{2j}+\sum_{j=0}^{N/2-1}e^{2\pi ik(2j+1)/N}f_{2j+1}\\ &=\sum_{j=0}^{N/2-1}e^{2\pi ikj/(N/2)}f_{2j}+W^{k}\sum_{j=0}^{N/2-1}e^{2\pi ikj/(N/2)}f_{2j+1}\\ &=F^{e}_{k}+W^{k}F^{o}_{k} \end{split} ��ѧ�ҽ�һ��������һ��Ϊ����DFT�飬һ����ԭ����ż���even����0,2,4,6...���ɵģ�����һ������ԭ���������odd����ɵġ������ֻ�ǿ�����һ�������Ѿ�������һ�������飬����ԭ���������ʽ����Ļ�����һ������Ҷ�任������Ҫ����N����ˣ���ֻ��Ҫodd���N/2�����㣬even���ֱ�Ӳ������κ�����ֱ���������ͺ��ˡ����������������ͼ���һ�����𣿵�����ʵ���鲢û����ô�����Ǹղ�֤�����κ�һ��DFT�鶼�ܱ�һ��Ϊ�������Ҽ��������롣������������һ��Ϊ���õ���even���odd�飬���Dz�����DFT�������ǿ��Լ���֮ǰ�IJ����������Ƿֱ��ٴη�Ϊ�����������ͣ� |
|
|
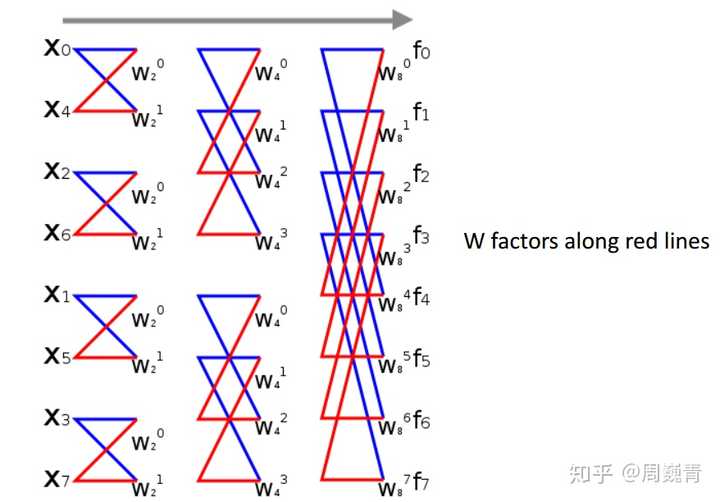
Fig.1 DFT��ϸ�ֹ��� һ��Ϊ��������Ϊ�ģ��ķ�Ϊ�ˣ�һֱ�ֵ�ÿ������ֻʣһ������Ϊֹ������ÿ����һ�β���������ʹ������һ��ļ����������١��������ǾͰѼ������� O(N2)" role="presentation">O(N2)O(N^{2}) ������ N×log2(N)" role="presentation">N��log2(N)N \times log_{2}(N) ����������ڶ�����㷨��ͻ���Ի�û�и�������������㹹���¸�� N=1024,N/log2(N)∼102N=8192,N/log2(N)∼630N=32768,N/log2(N)∼2185N=106,N/log2(N)∼50171" role="presentation">N=1024,N/log2(N)��102N=8192,N/log2(N)��630N=32768,N/log2(N)��2185N=106,N/log2(N)��50171N=1024, N/log_{2}(N)\sim102 \\ N=8192, N/log_{2}(N)\sim630 \\ N=32768, N/log_{2}(N)\sim2185 \\ N=10^{6}, N/log_{2}(N)\sim50171 ����N�����ӣ�FFT�㷨����DFT�����ƻ�����֣�һ��ʼ1024������FFT��DFT��100����32768�������Ϳ���2000�����������֮ǰ�ᵽ�ļ���1������������˽�5��FFT�����ǵļ����������������������һ�䣬����FFT���ȶ����Ŀ���FFTW�����W�ǡ�in West��������˵��������FFT�����ҵ�ʱ�տ���FFTʱ����������һ����д�������棬FFTE��FFT in East�������������Լ��ij����FFTW����һ�ȣ����˶�ɵ�ˣ���Ȼ�õ�FFT�����dz�����д�ġ� ����㷨�ؼ��Ĺؼ����ǽ�DFT�鲻����żϸ�֣�ϸ�ֵ����ʱ�����ȷ��ÿ������ǰ�����λϵ������ϣ����������ڵڶ��θ����а����ȷ��ϸ�ֺ�����У��Լ������㷨���ꡣ |
|
|
Fig.2 �����㷨 ���Ȱ��ҵ�ʱ��һ��һ�νӴ���FFT��д��FortranԴ���������ɡ��̶̼�ʮ�У�������ܻ������ʱ����������ݹ������ô�⽫��2020���õĵ�һ������������֪ʶ�� 2023.2.19 ��л�������Ľ��飬�� o" role="presentation">oo ��Ϊ O" role="presentation">OO �� |
|
��Ȼû��˵�����GitHub���õ�34k�ǵ���Ŀ���ѵ�֪���ϵij���Ա��ֻ��ٶȣ�����GitHub�� �����Ŀ���ƴ��棬��GitHub�ϱ������˳���Ϊ���ֱ�ѧ��Ŀ��ȴƫƫ�ֿ��������κ��ģ������κ�ƽ̨���汾��IDE�����ã�������0�ɱ����룬������ʷ������ΰ��Ĺ��̣�û��֮һ�� Ϊ������ԭ���ߣ�����ȥ��Ŀ�в鿴�������Ǽ������ʷ�ϵ�һ���ᱮ�� ������Ļ����ɲ������Լ����۵ģ����������ǵ����ԣ� |

|
|
|
|
|
|
|
|
|
|
|
|
|
|
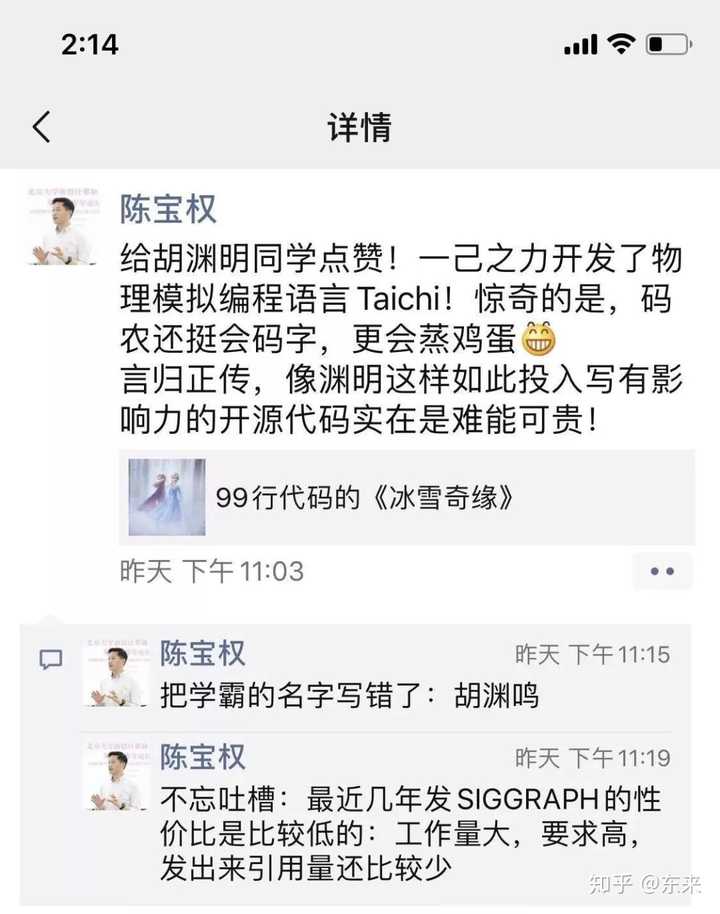
��Ҳ���Ҽ�����һ��������ϸ��û�ʽ���Կ佱����Ŀ������Book˼�飨����˼�飩�������ܶ����ã����ɵ����dz���������������Ԩ������������Ļ����佱�� ����GitHub������������˵��ȫ���㶼�Ҳ����ڶ�����������Ŀ�ˣ� ��Ŀ���ƣ�nocode ��Ŀ��ַ��https://github.com/kelseyhightower/nocode ������ƽ���ͣ���ϸ������Ŀ�ͻ����ף������Ŀ�᳹��git����ʵı��⡣ ���ҳ���Ա��ʵ�����ؾ��磺 1.�������룬�ü������������� 2.�������룬����Ҳ���룬���ڴ������������ڵ��� 3.�������룬����Ҳ���룬�����ǵ��� ֻ�е�������ؾ����������35������� �ҿ��������Ŀ֮��ĸ��룺 �ٸ��������Ӳ����Ŀ��99�д���ʵ�֡���ѩ��Ե���� ����ѩ��Ե��û�����˳��ݣ�Ԥ��ȴ�ߴ�1.5����Ԫ��ÿһ��ľ�ͷ���Ǿ�����ȼ�ա�һ�������õ�������CG��Ч��ֱ�������� Ȼ�������һλ�����й���MIT��ʿ������������ģ�������ԣ�Taichi ����˳ɱ��� �����ͼ��ѧ֪��ѧ�ߡ�������ڳ±�Ȩ�����ܸߵ����ۣ� |
|
��δ�����Python 3���С�����ǰҪ���ݲ���ϵͳ��CUDA�汾(�����CUDA�Ļ�)��װtaichi�� ��99�д�����Ȼ�̣ܶ��䱳��Ĺ���ȴ�ܳ��� ��Ȼ���������Python������㲿��ȴ�ᱻһ���ױ���ϵͳ�ӹܣ���������ִ�е�x86_64����PTX instructions���ܹ���CPU/GPU�ϸ�Ч���С� |

|
|
0 ��Ŀ��ַ��https://github.com/yuanming-hu/difftaichi �����Ķ��� GitHub ����ʲô�����ܴ�����������ѧ�� Python ��Ŀ��2763 ��ͬ �� 25 ���ۻش� |

|
|
��������˽������Ȥ���й۵㡢��֪ʶ�����ݣ������ǵ�� @���� ��ע�ң�һ����Ȥ������ĬĬ�ĵ����㣡 �һ�д�˲��١����ء����ݣ� ������������19��ĸ������ݣ�����̡����С����������飬�ü����ǵ�ƪ�������Ķ���Ӳ�˿������ݡ� ��19�괴���ĸ������ݣ���������4222 ��� �� 89 ��ע�ղؼ� |

|
|
|
|
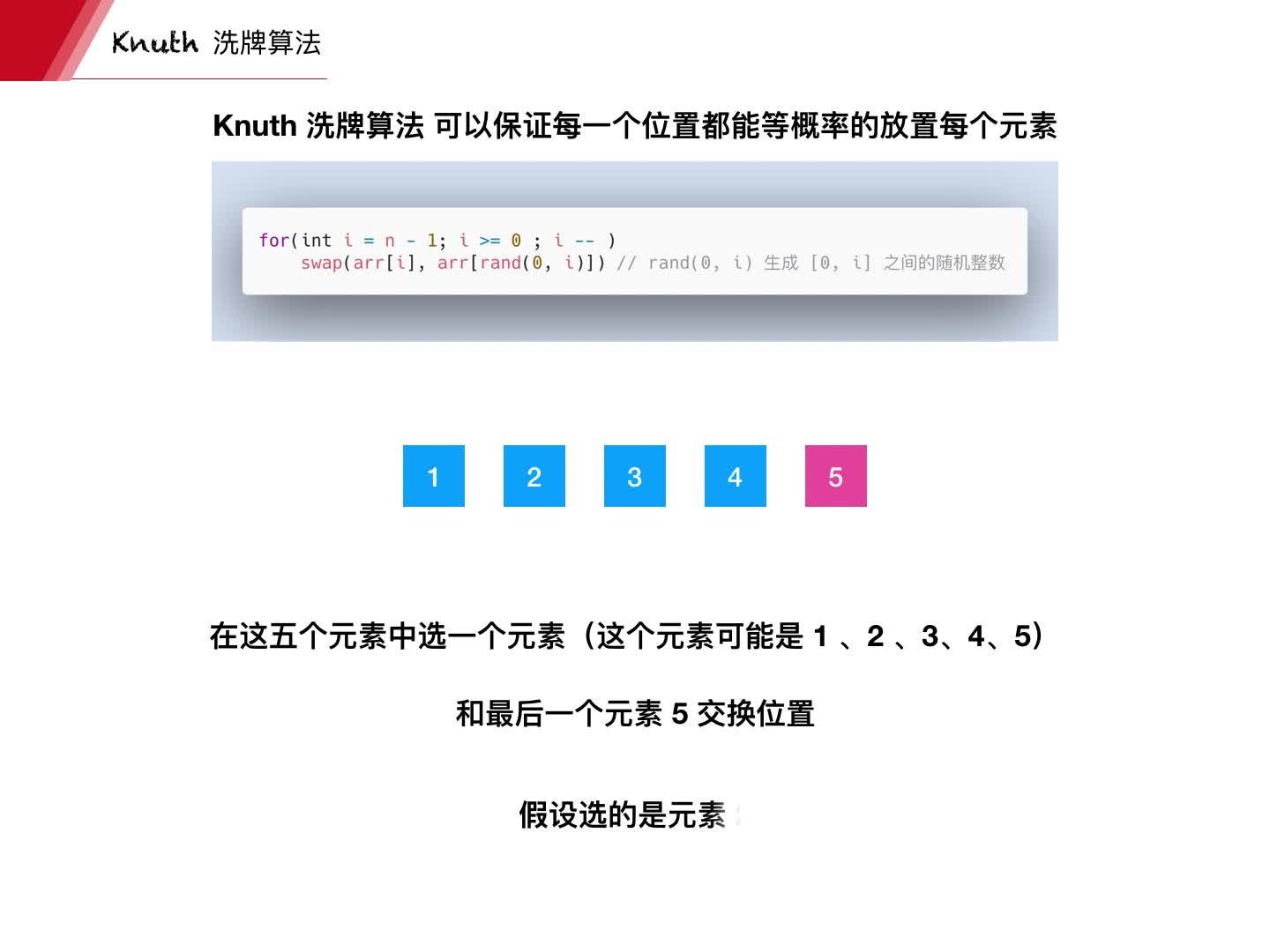
�еģ����� ϴ���㷨������㷨��ĺ�ţ�ƺܾ��䣬���Ҵ�����١� �������ö���У�Ĥ��ing���� ����˼��һ�����⣺��һ����СΪ 100 �����飬�����Ԫ���Ǵ� 1 �� 100 ��˳�����У���������Ĵ�����ѡ�� 1 ������ ��ķ���������ϵͳ�ķ��� Math.random() * 100 �������Ϳ����õ�һ�� 0 �� 99 ���������Ȼ��ȥ�����Ҷ�Ӧ��λ�þͼ��ɡ� ��������˼��һ�����⣺ ��һ����СΪ100�����飬�����Ԫ���Ǵ� 1 �� 100 ��˳�����У���������Ĵ�����ѡ�� 50 ������ ע�����ֲ����ظ��� ע�����ֲ����ظ��� ע�����ֲ����ظ��� ������������˼·�����һ�뷨�ǣ���� 50 �β������ˣ� ���ǣ��������и������Ե� bug �������ǻ��ظ��ġ� ��һ�£� Ūһ�����飬��ÿһ������������ŵ��������һ������Ϳ��������������û���������еĻ��ͼ��������ֱ��������������� 50 �����־�ֹͣ�� �����ǿ��Եģ� ���������и�С���⣬����һ�¼����������һ����СΪ100�����飬�����Ԫ���Ǵ� 1 �� 100 ��˳�����У���������Ĵ�����ѡ�� 99 ������ �����������ķ���������Խ����ѡ������ָ�ǰ���Ѿ���ѡ�������ظ��ĸ���Խ�ߣ���ͻ�����������ܴ�ѡ���������ĿҲ�ܴ�Ļ����ظ������������ϻ�ܴ� ���ʱ�����Ҫ��һ��˼·������Ƚ����������Ԫ�ش��ң���ô��˳��ѡ��ǰ 50 �����Ϳ����ˣ� �ǵģ� �����ǵ�ע��ʲô���ң� һ���˿��� 54 ���ƣ��� 54! �����з�ʽ����ν�Ĵ���ָ���ǣ�����ִ�еIJ�����Ӧ���ܹ� �ȸ��ʵ����� �� 54! �ֽ���е�һ�֡� ϴ���㷨����������һ�㡣 ϴ���㷨 Fisher�CYates shuffle �㷨�� Ronald Fisher �� Frank Yates �� 1938 ��������� 1964 ���� Richard Durstenfeld �ı�Ϊ�����ڵ��Ա�̵İ汾�� ����㷨��ţ��ȴ�ܺ����⣬ͨ�Ľ��;��ǣ������һ������ǰ������ n-1 �����е�һ�������н�����Ȼ�����ڶ�������ǰ������ n-2 �����е�һ�������н��������� |

|
|
С����ʵ�ִ��� �����������У�����㷨��֤��ÿһ��Ԫ�س�����ÿһ��λ�õĸ�������ȵġ� ����㷨��ĺ�ţ�ƺܾ��䣬���Ҵ�����١� ������һ����Ƶ���и������⡣ |
|
|
0 ϴ���㷨���� Ϊ�˱���֪�����о����Ҵ��ƣ�����һ���Լ��� GitHub ��ַ��Ŀǰ 70��000 star��ȫ������ 51 ���� https://github.com/MisterBooo |
|
|
�㷨��һ�ּ��ܣ��ǿ���ͨ����ѧ�����ķ�ʽѵ�������������� ����ˢ��֮ǰ���ô�������ʶ������ˢ�����Ҫ�����ܼ��ȥˢ�⡣ �����и����ԣ�����ˢ LeetCode������� 1 ���ϱ�������ˢ LeetCode ������� 10 ���ϱ��ˡ� Ϊʲô������ˢ���Լ۱���ô���أ� �����룬���濼 4 ���⣬һ����ֵ 5 ��λ�� Dollar �� |

|
|
ˢ������������ �����Dz��Ǻܴ̼�����û�ж�����ʼˢ���ˣ���������ˢ���ˣ� ��Ŀǰ�������������˵��������������������ڴ�����뻻������Ҫȥˢ�⣬һ����治���㼸�� Hard �⣬���Բ�ס��͵͵�����Ҹ������Ҽ�װ����ʵ�����Եļ����� ͬʱ��������ʶ��һ�㣬������������ƽʱ�Ĺ���������ʵ���ͦ��ġ� ��Щ�˼���ͦ�����ģ���û��ˢ�⣬һ����涼�����ˣ���ijЩС��ˢ��ң�����Ϳ�ˢ�������� Google����������ȴ�offer�� ���ڴ�Ҳ���������ƣ������ֽڣ�һ��붼�������⡣ |
|
|
Ҫ��������ǰ�ȿ���Ƶˢ�⣬���������� ���ԣ�ˢ�����Ҫ�� ��PS����л������ĵ��Ķ����㷨�dz���Ա������֮�أ����빥�ˣ������Աؿ���˳����һ�ݰ������ˢLeetcode�ܽ���㷨�ʼǣ�������ܳ�����������80%�ļ������Զ���ڻ��£� BAT����д��Leetcodeˢ��ʼǣ�������ɱ80%���㷨�⣡ �Ȿ���Ŀ¼���dz����䣺 |
|
|
ˢ���ſ��Է�Ϊ 4 ���Ρ� 1����С�ף���֪����ôˢ�⣬�Ժܶ�����İ�����������ݽṹ��֪ʶ�㼸����ȫ�������� LeetCode ��һ�⣬��ͷ�ʺš� �����మ������ҹ�↑������������ LeetCode ��һ�ⶼ���������� 2���㷨�ϻ����Ѿ����ţ�Easy ������������Medium �������Ҳ����ͷ�������������Σ������ַ�ת�ַ������� Google һ�¡� 3��ˢ�˼��ٵ�����ܽ����Լ��Ľ���ģ�壬�μ�������ʱ����������ȫ����ɡ� 4����ʼ�� beat 100% ��Ϊ AC ��Ŀ���ˡ� ��Ŀǰ���㷨���Դ���˵���ܴﵽ�ڶ��Σ���С��˾����Ӧ����ȥ�ˣ���������Σ��ֽڡ���Ѷ�㷨���Ի�������û�����ˡ� ��ô����������Σ� ��һ���ҵ�һЩС����ɡ� 1�����Ŀ���ǹ��ڴ���ôһ��Ҫˢ�㹻���⣬����Ҫ�� LeetCode �� 2500 ���㷨�ⶼˢ�꣬������ˢ 200 ���㷨��Ƶ�⣬��Щ��Ƶ���Ҷ�д�����ͬʱҲ¼������Ƶ�� ����������ܽ��ˣ�https://www.algomooc.com/1659.html 2������ǰһ���Կ���Ϊ������Ϊˢ��Ҳˢ���˼��⣬����Լ��ܽ���߱����ܽ��ģ�壬��������㷨ģ�壬���պ�ʮ�������ⶼ���ڻ��¡� һЩģ�壺 ���ݣ����ѣ�?mp.weixin.qq.com/s/2CLyNJtTnVQeEsy4fPC3Eg |

|
|
3��ˢ�������Ҫע���Ѷ�Ҫѭ�����㷨ѵ����һ��ϵͳ���̣���Ҫѭ����̫���ڼ������������������������������������ܸУ�������Ч���� ����㱾���л����������ȸߣ�����ˢ�� LeetCode Ӧ���Ǽ�����һ�⣬������һ��ģ������������ʱ�䡣 �����ˢ�����Ѻܳ�ʱ�䣬˵�������Ȳ�������Ӧ�ôӼ�ʼ��Ȼ����ȵ��еȣ��ٹ��ȵ����ѡ� ���ң�Ŀǰ���ڴ��㷨���죬�������ᳬ�� LeetCode �е��Ѷȣ������ѶȻ������� LeetCode �е���������е��Ѷȣ����Բ�Ҫ̫ȥ�����������ƫ�⡣ �Ѹ�Ƶ�����վ����ˣ�https://www.algomooc.com/1659.html ����һ������������ LeetCode ����Ŀ̫�ѣ������ȴӡ���ָ Offer���ϵ��㷨�ʼѧ�� Ϊ�˰�����Ҹ��õ�����ѧϰ�㷨����������Ļ��ۣ��Ҹ���Ҿ��ˡ���ָ Offer��ϵ�е���ʮ����Ŀ����϶�������ʽ¼������Ƶ�������ܰ�������õ�ˢ�⡣ |
|
|
��ȡ��ַ�� ������ָ Offer���ϵ��ⶼ����˶���?mp.weixin.qq.com/s/sk2kPb1rogmg9SmOfQ1nLw |

|
|
4�����㷨������ѡ�⣬����һ��ʱ��Σ�ֻˢ�����⣬ˢ�ò���ʱ��������ˢ���������⡣ �������м��������Եĺô��� һ��������ˢͬ�����͵���Ŀ�����Բ��ϵع��̺ͼ������⣬�����ܽ���Լ���˼��·�����߽���ģ�塣 ����������Ŀ���ͻ�ȥ˼������ͷ�ڵ㡢˫ָ�롢����ָ�롣 �������Ը�ȫ��ؽӴ�������ݽṹ���㷨�ĸ������֣�����ʹ���������ݽṹ���㷨���������ȫ�����̣�ѧϰ��Ч�ʻ���ߡ� ��һֱ��Ϊ�������������Լ۱���ߵijɳ���ʽ����ܱ��˵��������أ��������ǰ���ƽӹ����Խ�ķ�ʽ֮һ�� ���ڼ����רҵ��ѧ�����ԣ�������������鼮�����������������֪ʶ������������������У��֮���绢������ �鼮���أ�������ؿ������鼮�������ط�ʽ�� |

|
|
����ٸ�������ϵ�ɻ��� ��������һ�����ش�ϼ��������ҵ���&�ղأ�Markס���ˣ���ѧ�ڼ�����õ��ϡ� 1����ôѧ�����ݽṹ������������ش��Ѿ������ 21000+ ���� 50000+���ղء� 2�����ϵͳ��ѧϰ�㷨������������ش��Ѿ������ 11000+ ���� 26000+���ղء� 3�����ָ����ʹ�� GitHub������������ش�����ڴ�ѧ�ڼ��֪��ʹ�� GitHub ����ô����Զ��ͬ���ˡ� 4�����Ϊһ������ij���Ա����ô��Щ����Աƽʱ��ϲ�������̳��ô˵��Ҳ���ղ�һЩ�ɡ� 5�����۱�����ô˵���Ҷ��Ǽᶨ���Ƶ�ѡ������רҵ�� 6�����ϵͳ��ѧϰ C++ ������ش��ܰ����ҵ�·�ߡ� 7����Ҫ�� Java ���ԣ���ô��Щ������������ա� �Ͻ������ղذ�~ |

|
|
godweiyang 42 ����ѯ 5.0 �ֽ����� Ա�� 32999 ����ͬ ȥ��ѯ ������һ�������㷨��������⣺Լɪ�����⡣ �� n ����Χ��һ��Ȧ��ÿ q �����ߵ�һ���ˣ�����������������Ǽ��ţ� �Dz��Ǻ���Ϥ���������Ǹ�ѧ��ʱ����ô���ģ��Dz������������Dz���д��ʹ������������ʱ�ˣ�Ŷ���������ˡ� ����������������Ļ���ʱ�临�Ӷ��� O(qn) ��������������ķ��������Լ��ٵ� O(\log{n}) �� �����ҽ�һ��������ѧ���Ͻ����ļ��ⷨ�� �����ʼ���Ϊ 1,2,\ldots,n �����ڿ���һ���µı�ŷ�ʽ�� ��һ���˲��ᱻ�ߵ�����ô���ı�Ŵ� n ��ʼ����� 1 ����� n+1 ��Ȼ��ڶ����˱�ű�Ϊ n+2 ��ֱ���� q ���ˣ������ߵ��ˡ� Ȼ��� q+1 ���˱�ż����� 1 ������� n+q ��������ȥ�� ���ǵ�ǰ�ߵ����˱��Ϊ kq ����ô��ʱ�Ѿ��ߵ��� k ���ˣ����Խ���ȥ�����µı��Ϊ n + k(q - 1) + 1 \ldots �� ���Ա��Ϊ kq+d ���˱�ű���� n + k(q - 1) + d ������ qn ����������ô�����������Ƴ���ԭ���ı�ţ� �� n=10,q=3 Ϊ������ͼ����ÿ�����µı�ţ� |

|
|
�� N = n + k(q - 1) + d ����ô����һ�εı���� kq + d = kq + N - n - k(q - 1) = k + N - n ��Ϊ k = \frac{ {N - n - d}}{ {q - 1}} = \left\lfloor {\frac{ {N - n - 1}}{ {q - 1}}} \right\rfloor ������һ�α�ſ���дΪ \left\lfloor {\frac{ {N - n - 1}}{ {q - 1}}} \right\rfloor + N - n ����������˱�ſ��������µ��㷨���㣺 ���� k = \left\lfloor {\frac{ {N - n - 1}}{ {q - 1}}} \right\rfloor �� ��������� D = qn + 1 - N ��� N �������һ�����㷨�� \begin{array}{l}D = qn + 1 - N\\ = qn + 1 - \left( {\left\lfloor {\frac{ {(qn + 1 - D) - n - 1}}{ {q - 1}}} \right\rfloor + qn + 1 - D - n} \right)\\ = n + D - \left\lfloor {\frac{ {(q - 1)n - D}}{ {q - 1}}} \right\rfloor \\ = D - \left\lfloor {\frac{ { - D}}{ {q - 1}}} \right\rfloor \\ = D + \left\lceil {\frac{D}{ {q - 1}}} \right\rceil \\ = \left\lceil {\frac{q}{ {q - 1}}D} \right\rceil \end{array} �㷨α�������£� ���� k = \left\lceil {\frac{q}{ {q - 1}}D} \right\rceil �� ���������㷨�����һ������Լɪ����Ŀ����Ŀ���ӣ� ע����� n �ķ�Χ�ߴ� 10^{12} �������� O(qn) �ı������� O(n) �ĵݹ鶼��ԭ�ر�ըboom boom boom~ ��ʱ��͵ö�������ķ����ˡ� C++�������£� ��ϸ�ı���֪ʶ��д����ר������� ������ ��û�������������һ�����߰� |
|
Tomohiko Sakamoto �㷨����ȷ����ǰ���������ڼ� ���������٣����ٵ�ʵ�ַ�ʽֻ��һ�У����Ҳ�������С� �����൱���䣬��Ȼ�ˣ�����̫�������⡣ Tomohiko Sakamoto �㷨�����ʵ�ִ��룺 ͬʱ��Tomohiko Sakamoto ������������һ��������һ�а汾�� ���뿴�žͺ�Ư��������һ�»ᷢ��ȷʵ��Ư���� |

|
|
|

|
|
|

|
|
|
|
|
| [�ղر���] �����ر��ġ� |
| ��һƪ���� ��һƪ���� �鿴�������� |
|
|
|
| ��Ʊ�ǵ�ʵʱͳ�� ��ͣ��ѡ�� ��ʱͼѡ�� ��ͣ��ѡ�� K��ͼѡ�� �ɽ���ѡ�� ����ѡ�� ������ѡ�� �������� �������� ���� MACDָ�� KDJָ�� BOLLָ�� RSIָ�� ���ɻ���֪ʶ ���ɹ��� |
| ��վ��ϵ: qq:121756557 email:121756557@qq.com ����ƻ� |